


Dynamic Result Clustering Service /cluster Protocol
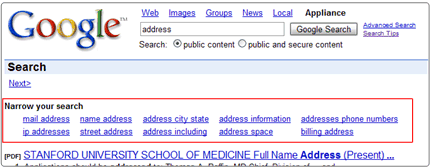
You can enable dynamic result clustering for a front end in the Admin Console at Search > Search Features > Front Ends > Output Format > Search Results > Dynamic result clusters.
<!-- *** dynamic result cluster options *** -->
<xsl:variable name="show_res_clusters">1</xsl:variable>
<xsl:variable name="res_cluster_position">position</xsl:variable>
Where position can be right or top.
When a user enters a query, the search appliance:
|
1.
|
|
2.
|
Fetches the /cluster content.
|
<xsl:when test="$res_cluster_position = ’top’">
<table>
<tr>
<td id=’cluster_label0’></td>
<td id=’cluster_label2’></td>
<td id=’cluster_label4’></td>
<td id=’cluster_label6’></td>
<td id=’cluster_label8’></td>
</tr>
<tr>
<td id=’cluster_label1’></td>
<td id=’cluster_label3’></td>
<td id=’cluster_label5’></td>
<td id=’cluster_label7’></td>
<td id=’cluster_label9’></td>
</tr>
</table>
</xsl:when>
<xsl:when test="$res_cluster_position = ’right’">
<ul>
<li id=’cluster_label0’></li>
<li id=’cluster_label1’></li>
<li id=’cluster_label2’></li>
<li id=’cluster_label3’></li>
<li id=’cluster_label4’></li>
<li id=’cluster_label5’></li>
<li id=’cluster_label6’></li>
<li id=’cluster_label7’></li>
<li id=’cluster_label8’></li>
<li id=’cluster_label9’></li>
</ul>
</xsl:when>
The default style sheet activates dynamic result clustering using onload attribute of the <body> tag on the search result page. The following is an example of the body opening tag:
<body onload="cs_loadClusters(’{search query}’, cs_drawClusters);">
Where {search_query} is the current search request, as shown in the following example (broken for readability):
q=culebra&btnG=Google+Search&access=p&client=default_frontend&output=xml_no_dtd&
proxystylesheet=default_frontend&sort=date%3AD%3AL%3Ad1&entqr=3&entsp=a&oe=UTF-8&
ie=UTF-8&ud=1&site=default_collection
The default XSLT stylesheet provides the clustering CSS id value for the page heading, cluster position, and loading message.
<div id=’clustering’>
<h3>Narrow your search</h3>
...
For more information, see Using Dynamic Result Clusters to Narrow Searches in Creating the Search Experience.
Note: The cluster.js file depends on additional JavaScript files listed in the application.
Dynamic Result Clustering Request
Administrators can test the /cluster feature by submitting a custom HTTP POST form.
The search appliance processes cluster requests:
|
1.
|
The cluster request inherits all request parameters and the search appliance transports the parameters into an internal search query. If any of the /search parameters (see Search Parameters) are present in the parameter list for the request to /cluster, they are passed to the internal search request.
|
|
Cluster output type: json or xml. Indicates the output you requested. Specify json for JSON output on /cluster POST requests. Specify xml for XML output as either a GET or POST. The xml value is generally used with /cluster as a RESTful service and the GET method. All request parameters must appear in the URI of a POST request. |
Dynamic Result Clustering JSON Request and Response
<html>
<head> <title> HTTP POST to view JSON for dynamic result clustering </title> </head>
<body>
<!-- Post parameters contiguous in a URL -->
<form method=’post’ action=’http://Search_Appliance/cluster?q=culebra&
btnG=Google+Search&access=p&entqr=0&ud=1&sort=date%3AD%3AL%3Ad1&
output=xml_no_dtd&oe=UTF-8&ie=UTF-8&client=default_frontend&
proxystylesheet=default_frontend&site=default_collection’>
<input type=submit value=’Post’></form>
</body>
</html>
Click the Post button to view the JSON response.
The search appliance returns the following JSON response:
{ "clusters": [
{ "algorithm": "Concepts",
"clusters": [
{ "label": "canada chile culebra",
"docs": [ 18,19,20,21,23,26,27,29,30,32]
},
{ "label": "dewey culebra",
"docs": [ 1,9,36]
}
]
}
],
"documents": [
{ "url": "http://server.example.com/file42.pdf",
"title": "TLA Annual Report 2009--Acronyms in the Public Sector
<b>...</b>",
"snippet": "<b>...</b> Soy Flz (<b>Culebra</b>) <b>Culebra</b>
34,102 34,102 2.28 <b>...</b> Soy Flz (<b>Culebra</b>)
was re-elected<br> Executive Director of <b>Culebra</b>,
effective May 1, 2009. <b>...</b>"
},
...,
{ "url": "http://server.example.com/turtle_island.html",
"title": "Puerto Rico Travel",
"snippet": "<b>...</b> rentals and useful information about <b>Culebra</b>
<b>...</b>"
}
]
}
The top-level entries are described in the following table.
|
The output from different clustering algorithms. There is only one supported cluster algorithm, so the value of algorithm must be Concepts. The clusters category consists of:
Each label provides an alternative query, and each docs array tells the document location indices. |
|||||||
|
A sequence of the URL, title, and snippet for each of up to 100 top search results from a search query. The search appliance creates the docs arrays from the documents list. |
The dynamic result clustering service’s default JavaScript client ignores the documents element and does not use the docs array.
Dynamic Result Clustering XML Request and Response
The POST form returns XML output by adding the coutput=xml parameter to the action= URL:
<form method=’post’ action=’http://Search_Appliance/
cluster?q=culebra&coutput=xml&btnG=Google+Search&access=p&entqr=0&ud=1&
sort=date%3AD%3AL%3Ad1&output=xml_no_dtd&oe=UTF-8&
ie=UTF-8&client=default_frontend&
proxystylesheet=default_frontend&site=default_collection’>
<input type=submit value=’Post’>
</form>
The search appliance returns the following XML response:
<?xml version="1.0"?>
<toplevel>
<Response>
<algorithm data="Concepts"/>
<t_cluster int="75"/>
<cluster>
<gcluster>
<label data="canada chile culebra"/>
<doc int="18"/>
<doc int="19"/>
<doc int="20"/>
<doc int="21"/>
<doc int="23"/>
<doc int="26"/>
<doc int="27"/>
<doc int="29"/>
<doc int="30"/>
<doc int="32"/>
</gcluster>
<gcluster>
<label data="dewey culebra"/>
<doc int="1"/>
<doc int="9"/>
<doc int="36"/>
</gcluster>
</cluster>
</Response>
<t_fetch int="134"/>
<document>
<url data="http://server.example.com/file42.pdf"/>
<title data="TLA Annual Report 2009--Acronyms in the Public Sector <b>...</b>"/>
<snippet data="<b>...</b> Soy Flz (<b>Culebra</b>) <b>Culebra</b>
34,102 34,102 2.28 <b>...</b> Soy Flz (<b>Culebra</b>)
was re-elected<br> Executive Director of <b>Culebra</b>,
effective May 1, 2009. <b>...</b>"/>
</document>
<!-- ... -->
<document>
<url data="http://server.example.com/turtle_island.html"/>
<title data="Puerto Rico Travel"/>
<snippet data="<b>...</b> rentals and useful information about <b>Culebra</b>
<b>...</b>"/>
</document>
</toplevel>
The top-level entries are described in the following table.
|
The output from different clustering algorithms. There is only one supported cluster algorithm, so the value of <algorithm> must be Concepts. The <cluster> category consists of:
Each <label> provides an alternative query, and each <doc> array provides the document location indices. |
|||||||
|
A sequence of the URL, title, and snippet for each of up to 100 top search results from a search query. The search appliance creates the <doc> arrays from the <document> list. |
The dynamic result clustering service’s default JavaScript client ignores the <document> element and does not use the <doc> array. The XML response is very basic, and does not use any validations such as a DTD or XML.
<?xml version="1.0"?>
<!ELEMENT toplevel (Response, t_fetch, document+)>
<!ELEMENT Response (algorithm, t_cluster, cluster)>
<!ELEMENT cluster (gcluster+)>
<!-- each gcluster element is an alternate query and its location indexes from the top results -->
<!ELEMENT gcluster (label, doc+)>
<!-- each document element is search result, complete with url, title, and snippet -->
<!ELEMENT document (url, title, snippet)>
<!ELEMENT algorithm EMPTY>
<!ELEMENT t_fetch EMPTY>
<!ELEMENT label EMPTY>
<!ELEMENT doc EMPTY>
<!ELEMENT url EMPTY>
<!ELEMENT title EMPTY>
<!ELEMENT snippet EMPTY>
<!ATTLIST algorithm
data (Concepts)>
<!ATTLIST t_cluster
int CDATA #REQUIRED>
<!ATTLIST label
data CDATA #REQUIRED>
<!ATTLIST doc
int CDATA #REQUIRED>
<!ATTLIST url
data CDATA #REQUIRED>
<!ATTLIST title
data CDATA #REQUIRED>
<!ATTLIST snippet
data CDATA #REQUIRED>