【正規表現】置換後の文字を、置換対象の値とする
たまに仕事で、あるディレクトリのファイルに含まれている文字列の中から特定のパターンを見つけないといけない時があります。
特定のパターンを見つけるのは、サクラエディタ等でGrepすればいいんです。
Grepとは
「global regular expression print」の略です。翻訳すると「グローバル正規表現表示」となります。正規表現って何?となりますが、正規表現とは、特定の文字を記号で表現する手法です。
例えば、サクラエディタで「Ctl+g」をキーボードで入力すると、Grep検索画面が開きます。
Grep検索画面で「条件」に正規表現を入力して検索すると、サクラエディタがGrepしてくれます。
実際にやってみると分かりやすいですが、「.*」で検索すると、すべての文字列がヒットします。
これは「.」が任意の1文字を表し、「*」が直前のパターンの0回以上の繰り返しを示すため、「任意の文字の0回以上の繰り返し」の箇所を抽出するからです。Grepする際は、その条件である正規表現を理解するのが必須となるわけです。
最近仕事で正規表現をしなくてはいけない状況があったわけです。
ざっくり言うと、「ある関数が使えなくなったから、プログラム全体からその関数が使用されている箇所を見つけて置き換えて」といった感じです。
分かりやすくするために、このブログの記事から「Drupal」といった関数が使えなくなってしまったとしましょう。
その場合、サクラエディタで「Ctl+g」を入力し、条件に「Drupal」と打てばいいわけです。
すると以下のような抽出結果になります。
□検索条件 "Drupal"
検索対象 *.*
フォルダ C:\
除外ファイル *.msi;*.exe;*.obj;*.pdb;*.ilk;*.res;*.pch;*.iobj;*.ipdb
除外フォルダ .git;.svn;.vs
(サブフォルダも検索)
(英大文字小文字を区別しない)
(正規表現:bregonig.dll Ver.4.20 with Onigmo 6.2.0)
(文字コードセットの自動判別)
(一致した行を出力)
C:\01_はじめての投稿です.html(24,10) [UTF-8]: <li>PHP(Drupal)</li>
C:\01_はじめての投稿です.html(71,29) [UTF-8]: <p>その結果、Drupalをインストールすることで本サイトを作りました。</p>
C:\01_はじめての投稿です.html(75,4) [UTF-8]: <p>Drupalについては、聞いたことがある人はほとんどいないんじゃないでしょうか。私も仕事で接するまで全く知りませんでした。</p>
C:\01_はじめての投稿です.html(77,4) [UTF-8]: <p>DrupalはWordPressの仲間で、CMS(Contents Management System)と呼ばれるものの一種です。特徴は色々ありますが、とにかく</p>
C:\01_はじめての投稿です.html(79,5) [UTF-8]: <h3>Drupalは日本語の情報量が少ない</h3>
C:\01_はじめての投稿です.html(81,18) [UTF-8]: <p>これによって、大体の日本人はDrupalでサイトを作るときに挫折します。私もしました。</p>
C:\01_はじめての投稿です.html(83,29) [UTF-8]: <p>ただ、これは勉強するチャンスだと思ったので、あえてDrupalに挑戦してみることにしました。</p>
C:\01_はじめての投稿です.html(89,29) [UTF-8]: <p>そんな私ですが、これから上記で挙げた言語やソフト、Drupalについての情報を投稿していきたいと思います。</p>
これで、まずは「Drupal」が使用されている場所が分かったわけです。
これは簡単ですよね。適当な文字でGrepすればいいだけですから。問題はここからです。
この例では検索結果を少ししか表示していませんが、検索結果が1000件を超えていて、すべての「Drupal」に対して、
それが関数なのか文字列なのかを目視で判断するしかないとします。
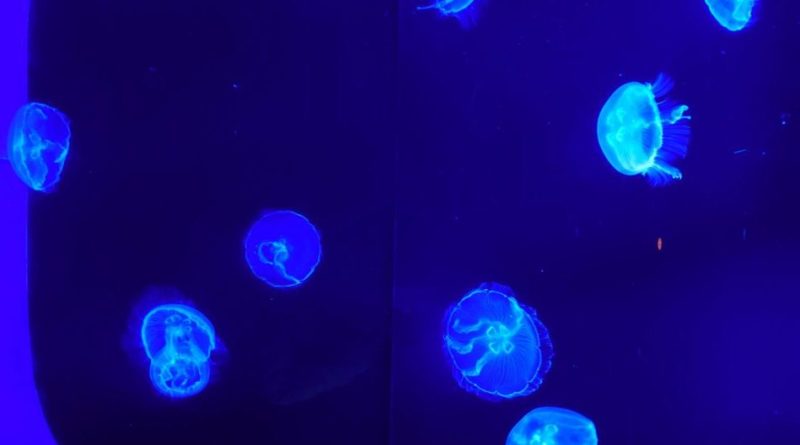
目視でしか確認できないのですが、一つ一つ確認するたびに確認済みチェックを入れる必要があったのです。例えば以下のような感じで。
C:\01_はじめての投稿です.html(24,10) [UTF-8]: <li>PHP(Drupal)</li> ⇒この「Drupal」は文字列であり、関数でないため対象外
そこで正規表現の出番です!
1000件以上の検索結果を一気に確認し、すべて文字列であれば、全て一括で確認済みチェックを入れたいですよね。
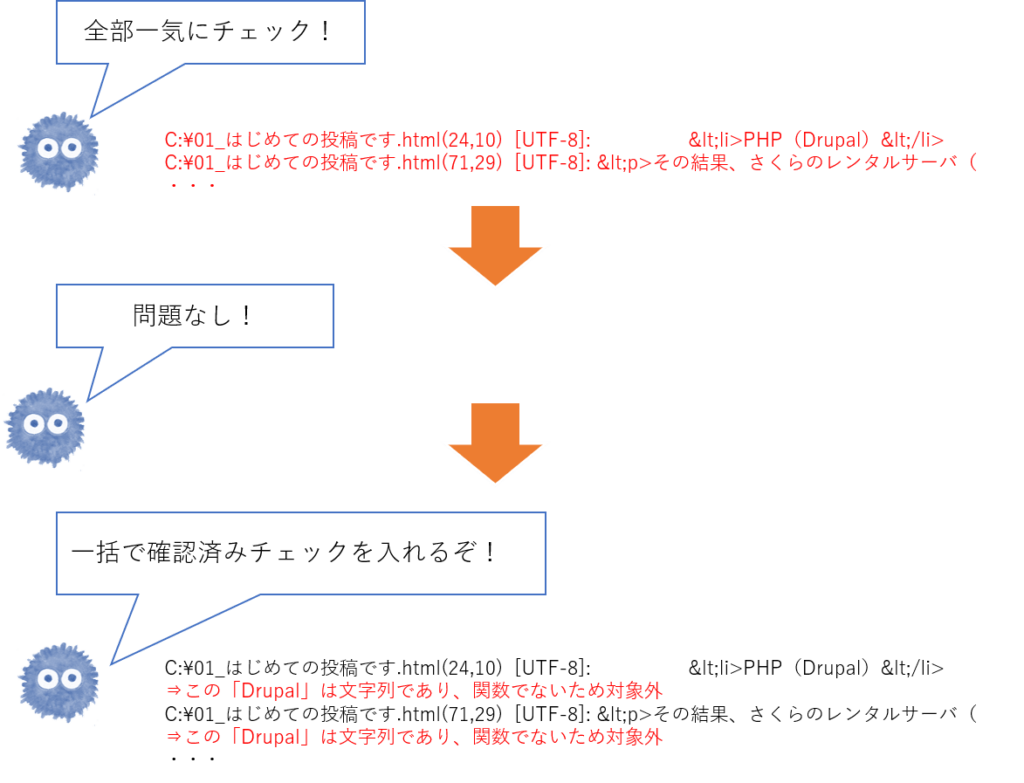
全て一括でチェック(文字を変換)する場合、サクラエディタで「Ctl+r」を入力すると置換画面が開き、「置換前」に正規表現を指定し、
「置換後」に変換後の文字列(チェック済み)を指定すればいいわけです。例えば以下のように、
「置換前」に「\r\n」、「置換後」に「\r\n⇒この「Drupal」は文字列であり、関数でないため対象外\r\n」として置換すれば、
全ての改行の後に「⇒この「Drupal」は文字列であり、関数でないため対象外がつくわけです。
C:\01_はじめての投稿です.html(24,10) [UTF-8]: <li>PHP(Drupal)</li> ⇒この「Drupal」は文字列であり、関数でないため対象外 C:\Users\une\Desktop\Drupal9開発\01_記事一覧\01_はじめての投稿です.html(24,10) [UTF-8]: <li>PHP(Drupal) ⇒この「Drupal」は文字列であり、関数でないため対象外 C:\Users\une\Desktop\Drupal9開発\01_記事一覧\01_はじめての投稿です.html(71,29) [UTF-8]: <p>その結果、にDrupalをインストールすることで本サイトを作りました。<li>/p> ⇒この「Drupal」は文字列であり、関数でないため対象外
ただし、この場合は全ての改行に対して置換が行われます。つまり、検索結果に関係ない箇所も「⇒この「Drupal」は文字列であり、関数でないため対象外」
がつくわけです。
□検索条件 "test" ⇒この「Drupal」は文字列であり、関数でないため対象外 検索対象 *.* ⇒この「Drupal」は文字列であり、関数でないため対象外 フォルダ 除外ファイル *.msi;*.exe;*.obj;*.pdb;*.ilk;*.res;*.pch;*.iobj;*.ipdb ⇒この「Drupal」は文字列であり、関数でないため対象外
検索結果に関係ない箇所はいったん削除すればいいじゃないかとか思いましたが、
正規表現で解決できない自分が許せなかったのです。
なので、「C:」から始まる行の「改行のみ」を抽出できないか。と考えたわけです
結果から言いますが、「置換前」に「(^C.*\r\n)」、「置換後」に「$1⇒この「Drupal」は文字列であり、関数でないため対象外\r\n」
を設定することで解決しました。ただ、この答えに行き着くまでにいろいろ悩んだのでその過程を以下に残したいと思います。。
①正規表現のパターンで抽出できないか
調べると、正規表現は以下のようなパターンがあるらしいです。(一部の正規表現のみ載せます。)
| 正規表現 | 説明 |
|---|---|
| . | 任意の1文字(\nは除く) |
| \w | アルファベット、アンダーバー、数字 |
| \W | アルファベット、アンダーバー、数字以外 |
| ^ | 先頭を示す |
| \r\n | 改行 |
| + | 直前のパターンの1回以上の繰り返し |
| * | 直前のパターンの0回以上の繰り返し |
上記のパターンでどうにかならないかと試したのですが、どれもダメでした。。
例:^C.* ←全部の文字列がヒットしてしまう
^C\w|^C\W ←全部の文字列がヒットしてしまう
どうすればいいのか考えていると、先読みと後読みを使ったパターンがあることを知りました。
これでどうにかなるのでは?と思ったわけでです。
②肯定先読み
肯定先読みパターンは以下のように記述します。
上記の「パターン」にヒットした場合、「パターン」の直前の位置がヒットします。
例①
(検索パターン)(?=全部)
(ヒット箇所)全
例②
(検索パターン)(?=文字列)
(ヒット箇所)文
肯定先読みで、改行(\r\n)を検索すればいけるのでは?と思ったのですが、(?=\r\n)とすると
全ての改行が指定されてしまいました。orz
③肯定後読み
肯定後読みパターンは以下のように記述します。
上記の「パターン」にヒットした場合、「パターン」の直後の位置がヒットします。
例①
(検索パターン)(?<=全部)
(ヒット箇所)の
例②
(検索パターン)(?<=文字列)
(ヒット箇所)が
おおー。これは、「^C.」で「C」から始まるすべての行を指定すると、改行以外の文字がヒットすることを利用し、
(?<=^C.*)で「「C:」から始まる行の改行」を抽出できるのではと思いました。
しかし、エラー「invalid pattern in look-behind」が出力されてしまいました。。orz
サクラエディタの後読みでは、長さ不定(パターンの文字列の長さが決まっていない)の表現はNGだそうで、、、
④否定先読み
否定先読みパターンは以下のように記述します。
上記の「パターン」にヒットした場合、「パターン」の直前以外の位置がヒットします。
例①
(検索パターン)(?!全部)
(ヒット箇所)「全」以外
例②
(検索パターン)(? (ヒット箇所)「が」以外
否定先読みと同じく、「「C:」から始まる行の改行」を抽出する方法が思いつかなかったです。。。orz
⑤いろいろ試したけど
上記を使用していろいろ試しました。
(?=^C:).$\r\n
(^C.)(?<=[((?<=\w)|(?<=\W))])\r\n
(?<=[((?<=\w)|(?<=\W))])\r\n
(?<=[^C.+])\r\n
全部だめだった―!!(笑)
なので「「C:」から始まる行の改行」を抽出するのは諦めて、置換後の文字列に目を向けたわけです。
するとなんと、$1,$2,$3を使えば、置換前のカッコ()で括った部分を表現できることを知ったわけです。
つまり、「置換前」に「(^C.*\r\n)」、「置換後」に「$1⇒この「Drupal」は文字列であり、関数でないため対象外\r\n」とすると、
「「C:」から始まる行(改行を含む)」を
「「「C:」から始まる行(改行を含む)」+⇒この「Drupal」は文字列であり、関数でないため対象外\r\n」
と置換することができるわけです!!!
知らないことは怖いことであると、改めて気づかされました。
正規表現の勉強は、この本を参考にすればいいかなと思います。