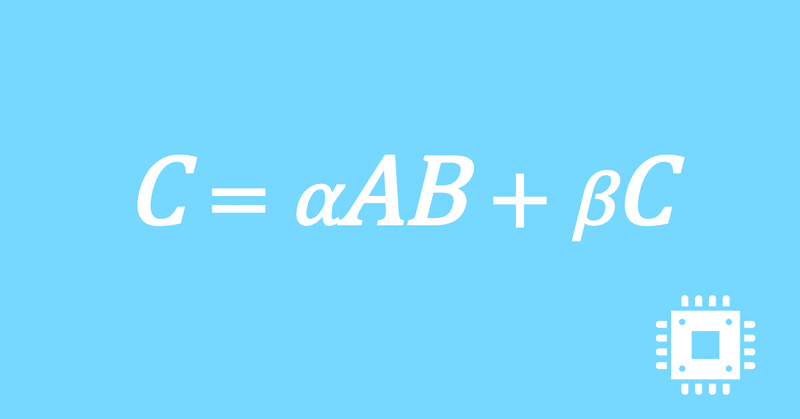
インラインアセンブラの書き方|行列積高速化#14

この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
アンローリングの次は、ベクトライズ(SIMD化)に取り組みます。現在のプログラムでもコンパイラがSIMD命令に置き換えてくれますが、残念ながら効率的ではありません。そこで、直接アセンブラ命令を指定し、強制的に効率的なベクトライズを行います。
しかし、全てをアセンブラ言語で記述するとなると、厄介な点があります。例えば、関数の引数はOS(WindowsやLinux)によって使用されるレジスタが異なる点などです。そうなると、OSの違いを吸収するプログラムが必要になります。このような性能への影響は小さい部分は、コンパイラに任せたいところです。
そこで、C言語の中にアセンブラ命令を埋め込めるインラインアセンブラ機能を使用します。
14-1. GCCインラインアセンブラの書き方
インラインアセンブラの詳細な記述方法は、「GCC Inline Assembler」や「GNUのマニュアル」を参考にしていただくことにして、ここでは今後使用する最低限の書き方を述べておきます。
gccのインラインアセンブラは、__asm__を使って次のような形式で記述します。
__asm__ __volatile__ ( /* コンパイラ最適化を停止__volatile__ */
"movsd 0(%[a]), %%xmm0 \n\t" /* AT&T形式 :"\t inst. ope2, ope1 \n" */
"movsd %%xmm0, 12*8(%[a],%[lda],$2) \n\t" /* アドレス指定形式:shift(addr,stride,n) = addr + stride*n + shift */
: [a]"=r"(A) /* 出力用変数を指定:"="書込可、"r"汎用レジスタ、[..]ラベル*/
: "0"(a),[lda]"r"(lda) /* 入力用変数を指定:"0"0番目の出力変数 */
: /* 破壊を退避したいレジスタを指定*/
);ダブルクォーテーション""で囲われた部分が、アセンブラ命令を記述するテンプレートになります。この中で使用されている%[a]などは、出力変数や入力変数として指定されたC言語の変数に置換されます。
gccでは、アセンブラ言語の記述方法として、基本的にIntel形式ではなくAT&T形式を用います。Intel形式とAT&T形式では、オペランドの並び順が逆になります。インテル社のマニュアル類は当然Intel形式で記述されているため、解釈に注意が必要です。
Intel形式
<instruction> <operand1>, <operand2>[, <operand3>]
AT&T形式
<instruction> [<operand3>, ]<operand2>, <operand1>
また、細かい点ですが、記述方法について、下記の点に注意が必要です。
・アセンブラテンプレートの文末にはタブ文字\tが必要です(行頭に必要なため)
・各レジスタは"%%"を頭につけます("%"に翻訳されます)
・アドレス指定形式が独特です。"shift(addr,stride,n)"は、addr+stride*n+shiftです。shift, strideはバイト単位で指定します。
・固定の整数は、"$2"のように"$"を付けて記述します。
14-2. コンパイラオプションの指定
この記事はプログラムを作りながら書いていますが、最も困った点がコンパイラオプションの指定不足でした。ターゲットアーキテクチャの指定が不足していました。
もともと、特にターゲットアーキテクチャを指定せずに、次のようにコンパイルしていました。
$ gcc -O3 -std=c11 -c myblas_dgemm.cしかし、このオプションでAVX2を使ったインラインアセンブラを1行でも挿入すると、様々な問題が起きました。
インラインアセンブラ(AVX2)挿入で起きた問題
(1)計算速度が1/3になってしまう
(2)計算結果が合わない(大部分は合っているが一部が合わない)
(3)関数呼び出しでSegmentation Faultが発生する
これらは、計算途中を確認しても、アセンブラ出力を確認しても理由がわかりませんでした。おそらく、プログラムの途中でレジスタが破壊されている、あるいは書き換わっているものと考えられます。
結局、インラインアセンブラでAVX2命令を使用せず、SSE2命令だけを使用したところ計算速度が低下しなかったため、ターゲットアーキテクチャをきちんと指定してみることにしました。gccでは、-mオプションでターゲットアーキテクチャを指定できます。
$ gcc -O3 -std=c11 -mavx2 -c myblas_dgemm.c結果として、-mオプションを指定することで、上記の問題は全て解消されました。そこで、以降、-mavx2オプションを付けてることにします。
14-3. 計算速度のチェック
コンパイラオプションを変更したので、計算速度に対するその影響を確認しておきましょう。
<-mavx2オプション追加前>
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 3.09944E-05, 289.084, 0.623027, 0.547508
32, 2.28882E-05, 2997.53, 6.46019, 5.67714
64, 0.000216961, 2473.15, 5.33006, 4.68399
128, 0.00110507, 3839.99, 8.27584, 7.2727
256, 0.00816512, 4133.56, 8.90854, 7.82872
512, 0.068949, 3904.65, 8.4152, 7.39518
1024, 0.499887, 4302.23, 9.27205, 8.14817
2048, 3.95995, 4341.58, 9.35685, 8.22269
<-mavx2オプション追加後>
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 3.8147E-05, 234.881, 0.506209, 0.44485
32, 2.90871E-05, 2358.71, 5.08343, 4.46726
64, 0.000140905, 3808.06, 8.20702, 7.21223
128, 0.000905037, 4688.71, 10.105, 8.88013
256, 0.00689793, 4892.93, 10.5451, 9.2669
512, 0.05779, 4658.62, 10.0401, 8.82315
1024, 0.42357, 5077.39, 10.9426, 9.61626
2048, 3.34036, 5146.89, 11.0924, 9.74789 結果として、-mavx2オプションの追加でわずかに計算速度が向上し、5,146 MFLOPSになりました。
次の記事
元の記事はこちらです。
ソースコードはGitHubに公開しています。
この記事が気に入ったらサポートをしてみませんか?