zfs の便利な機能 Top10
Linus が zfs を linux kernel にマージしないっていう姿勢がちょっと前に話題になっていたけど、
zfs の便利な機能を Top10 形式で出すので、zfs 広まって欲しい。
zfs をシステム管理で一度使ったことがある人にとっては、離れられないと思っている。
ただ、zfs は、もともと solaris (oracle) の機能であるので、
訴訟含めてどうなるかわからないのは、Linus の言うとおりなのかもしれない。
また、kernel にマージされていないのもあって、zfs on Linux では一部制限があったり
使いにくかったりしている。
tl;dr;
zfs を使うなら、ストレージ関連のコマンドとして、zpool, zfs という2つのコマンドを
知っていればよく、透過圧縮などもあり、ディスクを効率的に使用できる機能も盛り沢山。
ユーザーごとの使用容量も一瞬で表示できたり、スナップショットやバックアップ関連なども容易。
さらに、ソフトウェアRAID的な機能もあるのに、別な計算機に接続して使用したりするのも簡単。
#1 pool という概念による、容易なディスク追加
zfs はプールという概念で、ストレージを管理する。
考え方は lvm に似ているが、zfs ファイルシステムの機能の一部なので、
シームレスに使えるのが便利。
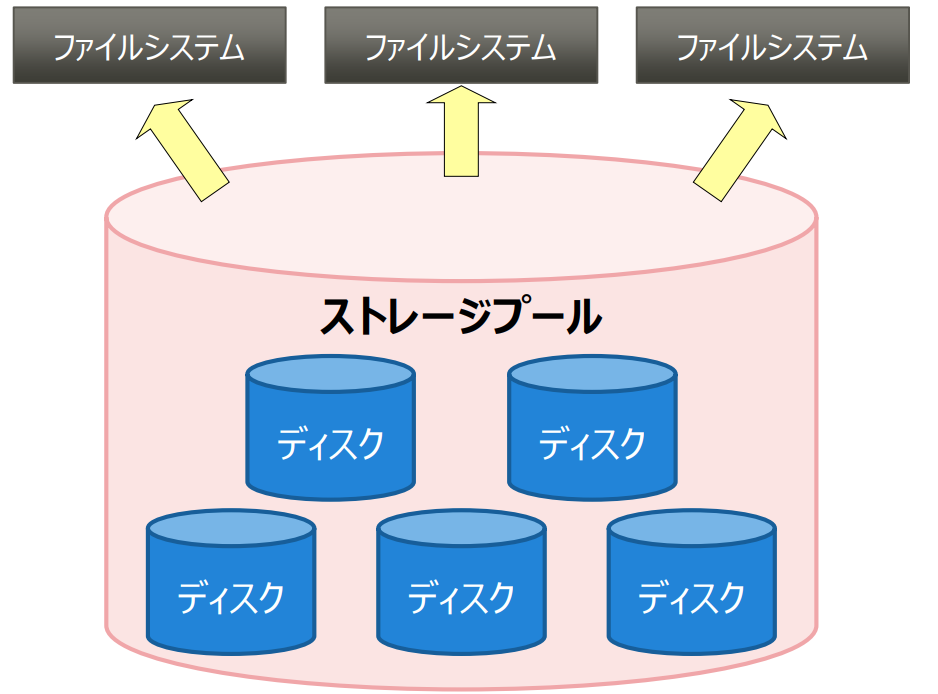
この概念があるのでデバイスを直接意識することなく使用することができ、
プールの容量を追加するときに、プールに対してディスクを追加すればよく、メンテなども行いやすい。
pool を作る時に software raid や mirror といったことも設定することができる。
また、プールの cache として高速な ssd を設定するといったこともできる。
$ zpool create tank raidz2 c1t0d0 c2t0d0 c3t0d0 c4t0d0 c5t0d0
$ zpool status -v tank
pool: tank
state: ONLINE
scrub: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
c1t0d0 ONLINE 0 0 0
c2t0d0 ONLINE 0 0 0
c3t0d0 ONLINE 0 0 0
c4t0d0 ONLINE 0 0 0
c5t0d0 ONLINE 0 0 0
#2 プロジェクトやユーザーごとのボリュームの管理の容易性
tank という名前の pool を作ったら、/tank などに自動的にマウントされて zfs として使用することができる。
そのまま、1つの pool を1つのファイルシステムとして使用することもできるが、
プロジェクトごとなど管理しやすい単位で pool から切り出して使用することができる。
pool から切り出すと、後述する snapshot やステータス情報、マウントポイントの変更、
一括した削除などが行いやすいので、ディレクトリ作成するようなイメージで作成すると良い。
もちろん構成の異なる複数の pool を作ることもできる。
$ zfs create tank/project_a
$ zfs create tank/project_b
$ zfs create tank/project_c
上記を行うと /tank/project_{a-c} というディレクトリが作られていて、そこに mount されているような形になる。
この時に、pool が共通なので全プロジェクトで共通のディスクを使用しているような形になる。
そのため、必要に応じて project ごとに使用量の上限値や、容量を確保することなどもできる。
$ zfs set quota=10G tank/project_a
$ zfs set reservation=5G tank/home/moore
zfs list などで zfs の情報を見ることができ、create した単位でどれぐらい使用しているのか
ということがすぐに確認できる。
$ zfs list
NAME USED AVAIL REFER MOUNTPOINT
pool 476K 16.5G 21K /pool
pool/clone 18K 16.5G 18K /pool/clone
pool/home 296K 16.5G 19K /pool/home
pool/home/marks 277K 16.5G 277K /pool/home/marks
pool/home/marks@snap 0 - 277K -
pool/test 18K 16.5G 18K /test
上記のように1段の階層だけではなく、/で区切って多段の階層も作ることができる。
/tank/project_{a-c} はデフォルトのマウントポイントで、任意の場所に変更も当然できる。
#3 ユーザーごとの使用量把握が一瞬
これは zfs 独特な便利な機能だと思っていて、同じファイルシステムを
複数ユーザーで使っている場合に、誰がどれぐらいディスク消費しているのか
ということを調べたい時があるけど、zfs ならそれが一瞬で表示できる。
group ごとの表示も可能で、それぞれ quota などの設定もできる。
$ zfs userspace students/compsci
TYPE NAME USED QUOTA
POSIX User root 227M none
POSIX User student1 455M 10G
$ zfs groupspace students/labstaff
TYPE NAME USED QUOTA
POSIX Group root 217M none
POSIX Group staff 217M 20G
ここら辺は単一のボリュームサイズが大きいほど、全部のデータを見にいくdu と比べてめちゃめちゃメリット。
同じステータス表示系ということで、ついでに iostat も紹介したい。
pool 自体の io も見ることができるが、-v(verbose mode) でみることで、
デバイスごとの io もここから把握できる。
pool ごとに接続されている デバイスを確認しやすくわかりやすい。
$ zpool iostat -v
capacity operations bandwidth
pool alloc free read write read write
---------- ----- ----- ----- ----- ----- -----
rpool 6.05G 61.9G 0 0 785 107
mirror 6.05G 61.9G 0 0 785 107
c1t0d0s0 - - 0 0 578 109
c1t1d0s0 - - 0 0 595 109
---------- ----- ----- ----- ----- ----- -----
tank 36.5G 31.5G 4 1 295K 146K
mirror 36.5G 31.5G 126 45 8.13M 4.01M
c1t2d0 - - 0 3 100K 386K
c1t3d0 - - 0 3 104K 386K
---------- ----- ----- ----- ----- ----- -----
#4 容易にアクセス可能なスナップショット
ストレージに snapshot 機能があるものもあるが、zfs 自体の機能を使うことで、
利便性が高いと思っている。
zfs で snapshot を作成する場合には、 zfs snapshot tank/project_a@friday のように
zfs の名前に @ をつけて作成するだけである。
snapshot の作成は一瞬で終わり、その後に変更部分だけが、
差分として残るので、コピーの様に重複してディスクを使用することもない。
solaris では自動スナップショットなどで、毎時や毎週などの自動的なスナップショットも
行えるが、 cron で同じようなことをすることもできる。
名前はあるていど自由に付けられるので、要所要所で snapshot をとることもできる。
#2 で説明した zfs create した単位で snapshot をとることができる。
-r オプションを指示することで、下位の階層全てのsnapshotをとることも可能
$ zfs snapshot -r tank/home@now
$ zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
rpool/ROOT/zfs2BE@zfs2BE 78.3M - 4.53G -
tank/home@now 0 - 26K -
tank/home/ahrens@now 0 - 259M -
tank/home/anne@now 0 - 156M -
tank/home/bob@now 0 - 156M -
tank/home/cindys@now 0 - 104M -
snapshot はアクセスの仕方も重要だと思うが、zfs の snapshot はアクセスも容易
$ zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
pool/home/anne@monday 0 - 780K -
pool/home/bob@monday 0 - 1.01M -
tank/home/ahrens@tuesday 8.50K - 780K -
tank/home/ahrens@wednesday 8.50K - 1.01M -
tank/home/ahrens@thursday 0 - 1.77M -
tank/home/cindys@today 8.50K - 524K -
上記のような状態であれば、 /tank/home/bob/.zfs/snapshot のような場所にアクセスすることで、
一般ユーザーでもすぐに snapshot にアクセスすることができる。
$ ls /tank/home/ahrens/.zfs/snapshot
tuesday wednesday thursday
.zfs は通常は見えていないが、アクセスしたら自動的に mount される形となる。
また、snapshot 同士でどのファイルに差分があるのかというのも確認できたりする。
$ zfs diff tank/home/tim@snap1 tank/home/tim@snap2
M /tank/home/tim/
+ /tank/home/tim/fileB
#5 透過圧縮ファイルシステム
ここらへんも馴染みが無い人も多いかも知れないけど、透過圧縮設定ができる。
ディスクに格納する時に圧縮して保存することで、ディスクの消費量を削減する仕組み。
透過とあるように通常使用する上で、圧縮されているかどうかは意識する必要がなく、
ls などで表示した場合にも通常の使用量で見えるが、ディスクには圧縮された状態で保存される。
テキストファイルが中心など圧縮に向いているデータが多い場合には、設定を ON にすれば効果が
高くなるが、当然CPU負荷も高くなる。
ただ、昨今はマルチコアでCPUが余っている場合も多いので、そういう場合にはメリットが大きい。
$ zfs set compress=on pool/fs
HDDのころは無圧縮のHDDに格納されたデータを転送するより、
圧縮して小さくなったデータを転送して、CPUで展開処理が早いので、
透過圧縮ファイルシステムを使った方がファイルIOが高いということもあったりした。
#6 重複ファイルシステム
ここら辺もあんまり馴染みない人もいるかも??
その名の通り、重複しているデータを同じものだと認識して、ディスク消費を防ぐ機能。
重複の判定は、ストレージに格納するときのブロックサイズごとで同じかどうかを判定するので、
一部分だけを変更したような時にも有効
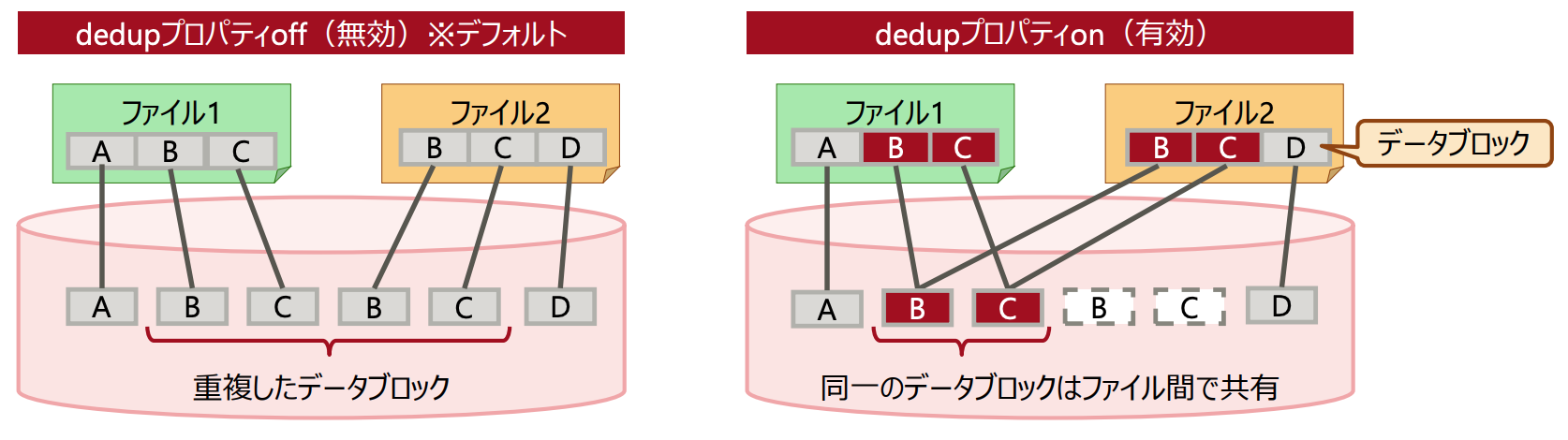
全く同じデータをコピーして使うような環境だとかなり効くやつ。
ただ、上記を読んですぐにわかる人もいるかもだけど、同じかどうか判定するために、ファイルシステムの
サイズに比例してメモリをかなり消費する。
zfs set dedup=on rz2pool/data1
#7 他の筐体へ移す際の容易性
pool という概念があるので、ディスクがどのように使われているか分からず、
もし本体が壊れた時とか、OSを入れ替えたい時に心配だという人もいるかもしれないけど、
OSが生きているなら export コマンドの取り外すコマンドを実行して、
新たな環境に全てのディスクつないで、 import を実行すると /dev/dsk/ 配下を
全部確認して、import できるディスクを探索してくれる。
$ zpool export tank
$ zpool import
pool: tank
id: 11809215114195894163
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
tank ONLINE
mirror-0 ONLINE
c1t0d0 ONLINE
c1t1d0 ONLINE
$ zpool import tank
また、ついでに紹介しておくと、ディスクまわりでは nfs 設定を設定するために、/etc/exports などを
設定することが多いが、zfs だとこの設定もファイルシステム上で設定すれば良い。
$ zfs set share=name=fs1,path=/rpool/fs1,prot=nfs rpool/fs1
この設定は、export, import してOS環境が変わっても、そのまま引き継がれるので、移行も容易。
$ zfs set sharenfs=on rpool/fs1
#8 バックアップの容易性
データを扱う上で、どうしても無くなったら困るファイルは、RAIDだけではなく
他のディスクなどにコピーすることもあると思う。
こういう時に使えるのが、send, recv
ディスクのボリュームが大きければ大きいほど、rsync とかでもコピーするのはなかなか辛い。
zfs では #4 で説明したスナップショット機能と連携して、
snapshot した時のデータをそのままストリームデータとして send できる。
二つの snapshot があれば、その差分だけを送付することも可能。
以下のコマンド例はそのまま別ホストで受けて、recv しているけど、
tgz とかの単一ファイルで残しておくこともできる。
$ zfs send -i tank/dana@snap1 tank/dana@snap2 | ssh host2 zfs recv newtank/dana
#9 統一されたコマンド群
ここまでのコマンド例を見て分かるように、
zpool, zfs という 2つのコマンドしか使用していない。
その2つを主コマンドとして機能ごとにサブコマンドで分ける形になっている。
git や docker などのコマンドと似たような構成になっている。
pvs, vgs, lvm, lvs, mkfs などなどどのコマンド使うんだっけと悩むことが少ない。
zpool iostat や zfs に関するコマンドの履歴を表示するzpool history など
ストレージに関することは全てこの2つのコマンドに任せる形で運用することができる。
$ zpool history
History for 'newpool:'
2007-04-25.11:37:31 zpool create newpool mirror c0t8d0 c0t10d0
2007-04-25.11:37:46 zpool replace newpool c0t10d0 c0t9d0
2007-04-25.11:38:04 zpool attach newpool c0t9d0 c0t11d0
2007-04-25.11:38:09 zfs create newpool/user1
2007-04-25.11:38:15 zfs destroy newpool/user1
厳密には、zdb という関連コマンドもあるが、必須コマンドではない。
#10 信頼性
データを扱う上で、信頼性が一番最後に来るのも微妙な気もするが、
ここはあって当たり前の必然な機能。
特に zfs では独自の通常のRAID5などよりも信頼性を高めた RAID-Z の
ような機能もあって、特に信頼性には力を入れている気がする。
zfs はこんなに高機能なのに、初版から 10年以上経過しているし、
最近は ubuntu がサポートを強化したりしていたりもするので、ほんと流行って欲しい。
もともと solaris の機能ということで、oracle や 富士通から
情報が提供されているので、正式な情報はそちらで確認してもらいたい。
引用元
https://docs.oracle.com/cd/E24845_01/html/819-6260/zfsover-1.html
https://www.fujitsu.com/jp/documents/products/computing/servers/unix/sparc/technical/document/solaris11_zfs_gde01.pdf
https://www.fujitsu.com/jp/documents/products/computing/servers/unix/sparc-enterprise/technical/documents/00_ZFS.pdf
https://www.fujitsu.com/jp/documents/products/computing/servers/unix/sparc-enterprise/technical/documents/zfs_apply.pdf