概要
UE4でクロス(布)シミュレーションをコンピュートシェーダで行うサンプルプロジェクトを作りました。
エンジン改造はせず、プロジェクトプラグインとして実装しています。
Githubにあげています。
何かいけてないことがあれば何でもご指摘ください。
レイトレーシングについては現状では配慮できてません。
Githubレポジトリ
動機
前回の記事でグリッド形状のメッシュをコンピュートシェーダで変形させるための土台作りをしました。
前回の記事
今回は、それを用いて最低限のクロスシミュレーションをやってみました。
せっかくなので公開しました。
スクリーンショット
ClothGridDemoマップのプレー中
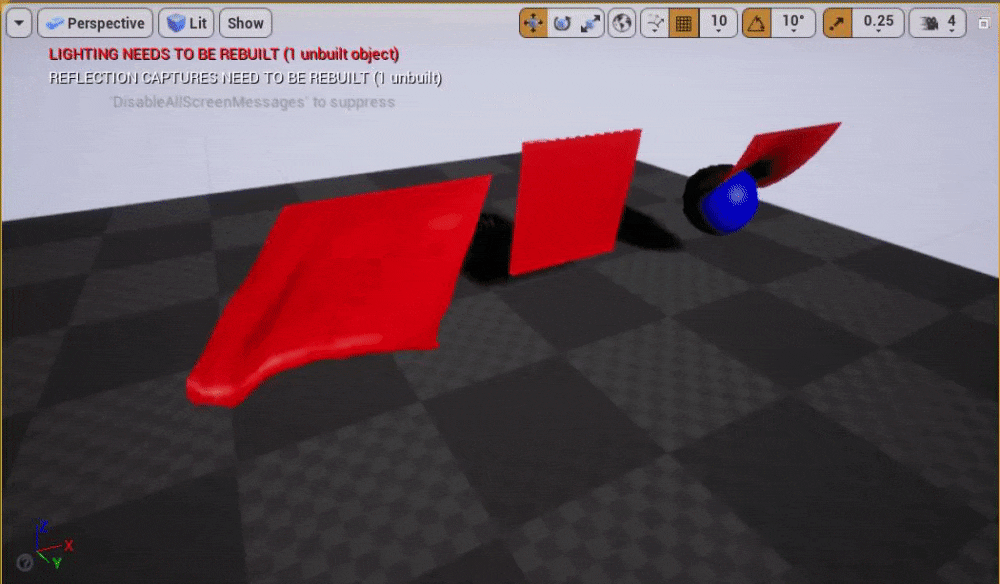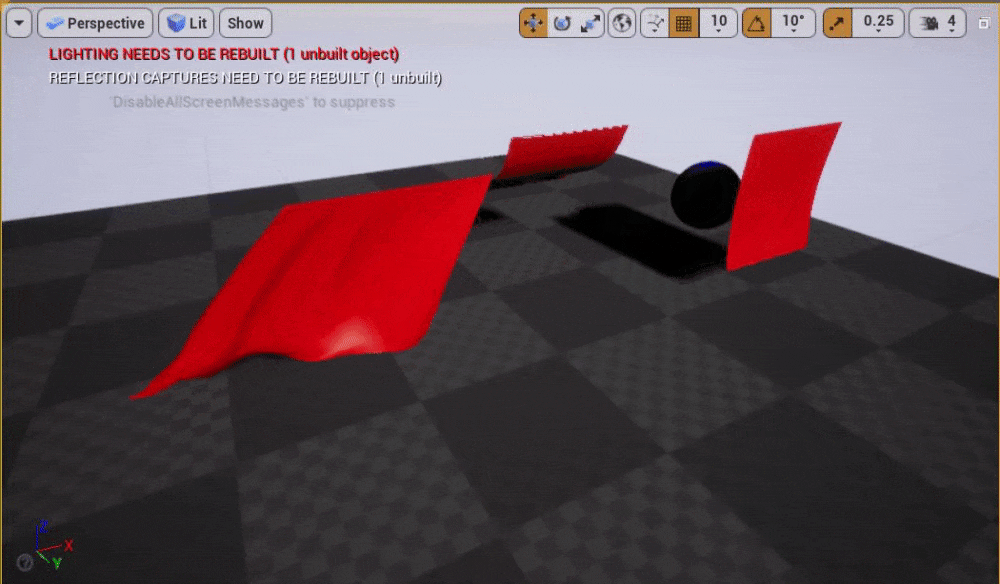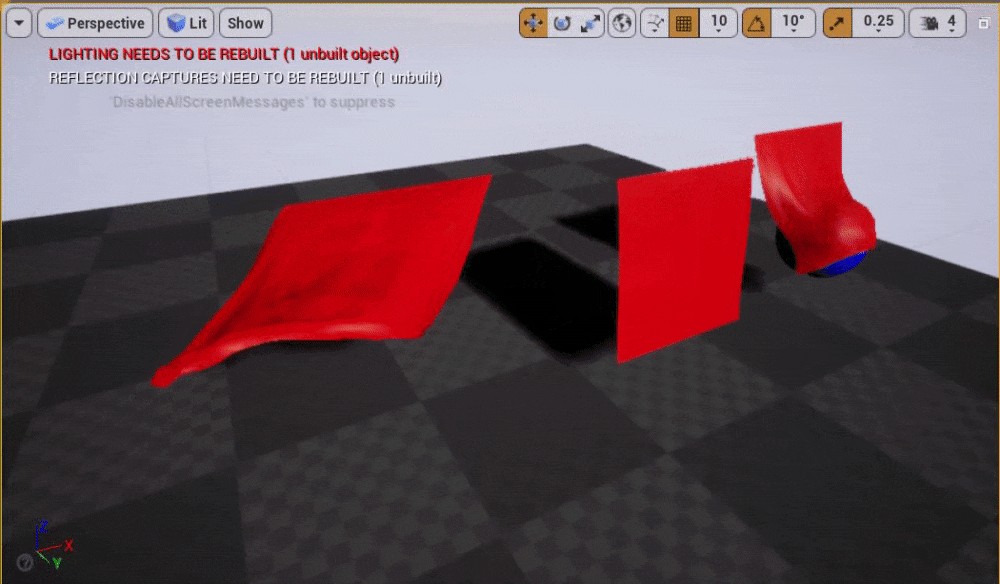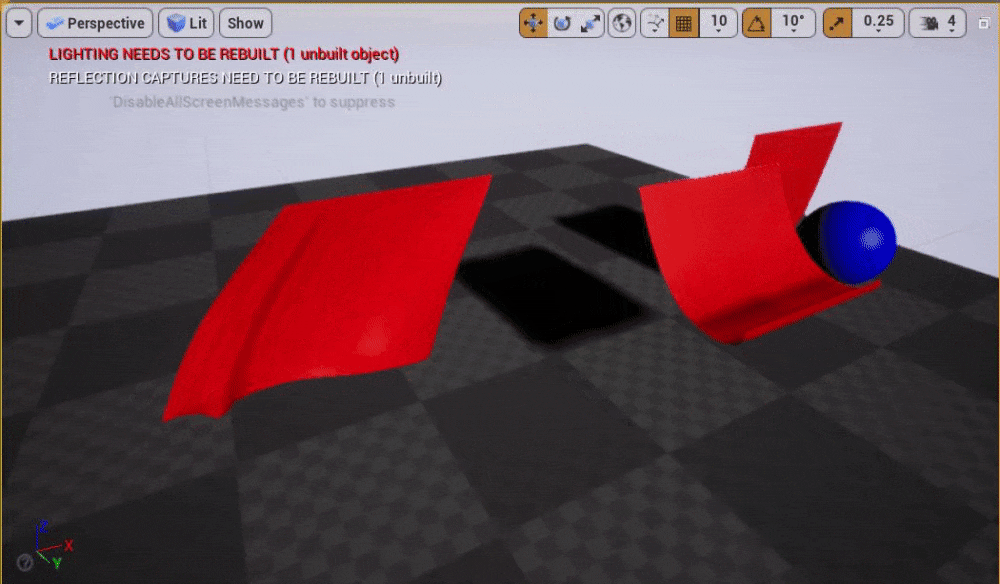
クロスシミュレーションの基礎知識
クロスシミュレーションのアルゴリズムについて、公開されていて、かつ、わかりやすい情報元となると僕は知りません。
(知ってる方はぜひ教えてください!)
ここではソースコードを読む際の参考になるように、アルゴリズムのごく簡易な説明をしたいと思います。
なるべく簡単に説明するために、説明の厳密な正しさは犠牲にしています。
クロスシミュレーションは頂点の物理シミュレーションです。
頂点を質点として扱います。
質点が自由粒子であればニュートン方程式の計算で終わりです。
しかし、質点が完全な自由粒子なら、空気抵抗なしの重力下では落下しかしません。
そこで、メッシュ内のいくつかの頂点は空間に固定される設定にしたうえで、頂点間の元の距離を維持するような制限をかけて、自由落下を防ぎます。
このような制限を物理シミュレーションではコンストレイント(拘束)と呼びます。
今回用いるコンストレイントは、頂点間の距離を維持するコンストレイントなので距離コンストレイントと呼んでいます。
クロスシミュレーションの分野では今でも様々なアルゴリズムの研究がされているようですが、今回は以下のようなシミュレーションの流れとなっています。
ソースコードで言うとClothGridMeshDefomer.cppとClothSimulationGridMesh.usfにあたります。
- 1フレームで行う処理
- 以下の計算工程を何周かループする。1周にかける時間をdtとする。
- Integrate ・・・ ニュートン方程式で、dtだけ進んだ位置を計算する(積分するという言い方をする)。ベルレ積分というアルゴリズムを使う。必須の工程。
- ApplyWind ・・・ 風力、空気抵抗の影響を計算する。風力、空気抵抗を考慮するなら必要。
- SolveDistanceConstraint ・・・ 頂点間の距離を維持するように位置を修正する。コンストレイントは「解く」という言い方をするのでSolve。必須の工程。
- SolveCollision ・・・ 他オブジェクトとのコリジョンの影響を計算する。コリジョンを考慮するなら必要。
- 以下の計算工程を何周かループする。1周にかける時間をdtとする。
物理の古典力学を勉強した人なら、風力、空気抵抗は加速度として、距離コンストレイント、コリジョンは境界条件としてニュートン方程式に取り込んだ上で方程式を解かねばならないと考えると思いますが、クロスシミュレーションの多くは上のようなアルゴリズムを採用しています。
小さなdtで位置を更新していけば、ゲームのような絵が良ければいいという分野には、十分な絵がこれで得られます。
製品レベルのクロスライブラリでは、クロスメッシュの頂点同士の衝突や、折れ曲がりの制限も考えますし、ユーザが頂点の動く範囲を制御したり、重力以外の外力を与えるような機能もあります。
そういうものは、別の工程として上のループ内に追加されます。
今回のクロスの状況設定であれば、上記4工程だけでもそれなりに見栄えのする絵になってくれます。
以上で説明は終わりです。
実装の補足説明
本記事では、ソースコードを部分的にとりあげて解説するようなことはせず、ソースコードを読んでみたい方の補助となることを目的として補足説明を記載しました。
まずは前回の記事および前回のソースコードを見ていただく方が導入がスムーズだと思います。
前回の記事
そちらの方がソースコードが短く読み解きやすいですし、本記事では前回説明したことは記載していないからです。
全体的な実装方針として、なるべく読みやすくなるように、最小限の実装にすることを心がけました。
そのため、クロスシミュレーションの最低限のサンプルにはなっていますが、実用用途には機能不足すぎますし最適化の余地があります。
前回SinWaveGridMeshComponentのために作ったDeformableVertexBuffersを継承し、ClothVertexBuffersとして、さらにいくつかのVBを追加しています。
前フレーム位置を保持するためのVBと、頂点ごとの加速度を保持するためのVBです。
SphereCollisionComponentというのは、球形のコライダブルを表現するための専用コンポーネントです。
ClothGridMeshComponent、ClothGridMeshSceneProxy、ClothGridMeshDeformerの関係性は、前回のSinWaveGridMeshComponent、SinWaveGridMeshSceneProxy、SinWaveGridMeshDeformerの関係性とほぼ同じです。
一点違うのは、今回はClothManagerという、レベル内にあるClothGridMeshComponentとSphereCollisionComponentすべてをまとめて管理するアクタを作っていることです。
レベル内には、ClothManagerアクタを必ず1個配置することを前提としています。
これは、レベル内にある複数の球コライダブルと複数のクロスのコリジョンを総当たりで扱うために、一括して描画パスに渡さないとならないため、また、その描画パスで複数のクロスメッシュのシミュレーションを将来的に1Dispatchで扱えるようにするためです。
ClothGridMeshDeformerではいくつかのコンピュートシェーダのDispatchを行っています。
FGlobalShader派生構造体は名前の通り、FClothSimulationIntegrationCSが上記説明のIntegrateに対応しています。
FClothSimulationApplyWindCS、FClothSimulationSolveDistanceConstraintCS、FClothSimulationSolveCollisionCSについても同じです。
SinWaveGridMeshDeformerのときと同様にFClothGridMeshTangentCSで頂点の法線と接線の修正を行っています。
球とコリジョンしているクロスアクタがハイライトがちらちらしていますが、おそらくメッシュが粗いことで法線の動きも粗いからではないかと思っています。
物理シミュレーション計算はClothSimulationGridMesh.usfに収まっています。
シミュレーションはClothGridMeshComponentのコンポーネント座標系で行っています。
おすすめの参考資料
NvClothドキュメント
https://gameworksdocs.nvidia.com/NvCloth/1.1/UserGuide/Index.html
https://gameworksdocs.nvidia.com/APEX/1.4/docs/APEX_Clothing/Index.html
NVIDIAがGAMEWORKSという一連のゲーム開発用の物理シミュレーションライブラリを提供しており、NvClothはその中のクロスシミュレーションライブラリです。
APEX ClothというのはNvClothをリリースする前にNVIDIAがリリースしていたクロスシミュレーションライブラリで、こちらの方がドキュメントが厚いです。
サンプルプロジェクトのビルドもできるはず。。
NvClothはPC向けのソースコードはGithubでプライベートリポジトリがあり、確か、GithubでNVIDIA GAMEWORKSのユーザアカウント作って規約に同意すれば誰でも見れるはず。
ライセンスの扱いには気をつけることを推奨します。
https://github.com/NVIDIAGameWorks/NvCloth
UE4のソースコード
StructuredBufferのUE4での書き方としてLandscapeEditLayers.cppとLandscapeLayersCS.usfが参考になりました。
未実装項目
最低限の機能しか作っていないため、以下のような一般のクロスライブラリがもつ機能には対応していません。
- クロスアクタの配置時の回転に対応していません。
- 慣性は並進運動にのみ対応。回転には未対応。
- コライダブルは球形にのみ対応。他形状は未対応。
- 可変フレームレート、可変イテレーション数未対応。60FPS、イテレーション数固定でテストしています。変えると動きが変わります。 (2020/01/05追記 可変フレームレートに対応しました。厳密ではないですが、ある程度の対応をしています。60FPSを基準にしていて、その周辺のFPSであればある程度フレームレートが変化してもクロスの特性を維持します)
- コリジョンは総当たり。ブロードフェイズなどはなし。
- 重力以外の外力付与に未対応。
課題
最適化で多くの課題を残しています。
コンピュートシェーダなのでなるべく並列化したいですが、シングルスレッドの部分が大半です。
現状ではメッシュごとにスレッドグループ数が1でDispatchしていますし、各シミュレーション工程ごとにDispatchしてますし、グループ内のスレッド数もいくつかの工程は32にしてますが、いくつかは1のままです。
最初はすべての工程がスレッド数1にしており、そこから2工程を32スレッドにしただけで手持ちのPCで42FPSから55FPSに上がったので、並列化による最適化の余地は大きいでしょう。
1Dispatchにまとめるにはシーン内の全クロスメッシュを1つのバッファとして扱うことと、グループ内をマルチスレッドにしているなら工程ごとの全頂点計算の同期待ちが必要となります。
FLocalVertexFactoryは各メッシュに対してひとつのSRVを要求するため、FLocalVertexFactoryを使い続けるにしても、代わりに自作のVertexFactoryを作るにしても、手間がすこし必要そうだったので先に公開しました。
全頂点位置の計算待ちをするなら、GroupMemoryBarrierWithGroupSync()とグループ共有メモリの使用が必須となると考えています。
今回は、愚直に各工程ごとにRWBufferに書き込んでいます。
グループ内のマルチスレッド化はIntegrateとSolveCollisionのような各頂点の依存性がないものに関しては行いましたが、SolveDistanceConstraintとApplyWindについては、見栄えを悪化させずに達成することができず、1スレッドのままにしています。
最適化は、今後も少しずつやっていこうと思っています。
そもそも検証としては、やってることが簡易すぎて、実装上の問題を見落としているかもしれません。
最小の実装とするためにFLocalVertexFactoryを流用し、FStaticMeshBuffersを真似しましたが、業務レベルでちゃんとやるならFRWBufferを使って専用のバッファを実装し、バーテックスファクトリも専用のものを実装すると思います。
また、ちゃんと使うなら、用途に応じて、パスをはさむタイミング、非同期コンピュートの検討、パフォーマンス測定、バッファフォーマットの検討などいろいろ考えねばなりませんね。
それはまた別の機会に書かせていただくかもしれません。
最適化
2020/01/03更新
RenderDocやGPU Visualizerは使わずにStat FPSやStat Unitだけで測定してました。
とはいえ、Stat UnitでGPUネックなのはわかっていました。
上の課題の節に書いてますが、明らかな最適化課題は以下のとおりでした。
1. SolveDistanceConstraintとApplyWindの工程がマルチスレッドで処理できてない
2. シミュレーション工程ごとにDispatchしている
3. クロスメッシュごとにDispatchしている
1についてはいまだに解決できていません。
2,3については対応しました。
上では、1メッシュ化できないのはFLocalVertexFactoryのせいみたいに書いてますが、そもそも、各クロスメッシュが別のマテリアルを使っている場合は、ベースパス投入時に別のドローコールにせざるを得ず、ベースパスをエンジン改造しないと1メッシュだと無理なのではないかと考えなおしました。
これについてはソースコードをちゃんと読んでないので、無根拠です。
ここでは、シミュレーションの前に全クロスメッシュのVBを、あらかじめ用意した大きなVBにコピーしてつめこみ、大きなVBでシミュレートして、シミュレーション後に各クロスメッシュに書き戻すようにすることで、1メッシュ化しました。
これで、2,3を実現しました。
2を実現するには全工程でスレッド数の定義を同じにせねばならないので、グループ数はクロスメッシ数、1グループ32スレッドとしたうえで、SolveDistanceConstraintとApplyWindはスレッド0のみに処理させる形にしました。
これで、手持ちのPCでは14ms、70FPSまで最適化できました。
最初、まったく並列化してないときは24ms、42FPSだったので、ましになりました。
現状でのGPU Visualizerの結果を貼ります。
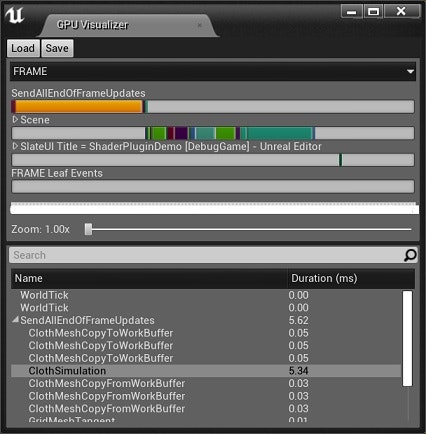
やはりClothSimulationの5.34msが大きいです。
3枚のクロスをすべて1フレームに5周シミュレーションした上での処理時間です。
このパスはベースパス前に終わらせておく必要があるので、次のフレームで現フレームのシミュレーション結果を使うことにして、他の描画パスと並列化すればかなり改善するかもしれません。
もちろん、このパス自体の最適化もしたいです。
相変わらずUAVをワークメモリ代わりにしているので、共有メモリを使うとパフォーマンスがよくなるのかも検証してみたいです。