WO2017209122A1 - 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 - Google Patents
標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 Download PDFInfo
- Publication number
- WO2017209122A1 WO2017209122A1 PCT/JP2017/020076 JP2017020076W WO2017209122A1 WO 2017209122 A1 WO2017209122 A1 WO 2017209122A1 JP 2017020076 W JP2017020076 W JP 2017020076W WO 2017209122 A1 WO2017209122 A1 WO 2017209122A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- asparagine
- fusion protein
- amino acids
- aspartic acid
- ppr
- Prior art date
Links
- 108090000623 proteins and genes Proteins 0.000 title claims abstract description 67
- 102000004169 proteins and genes Human genes 0.000 title claims abstract description 59
- 108020004999 messenger RNA Proteins 0.000 title claims abstract description 54
- 108020001507 fusion proteins Proteins 0.000 title claims abstract description 50
- 230000014509 gene expression Effects 0.000 title claims abstract description 25
- 230000027455 binding Effects 0.000 claims abstract description 62
- 102000037865 fusion proteins Human genes 0.000 claims abstract description 49
- 108091032973 (ribonucleotides)n+m Proteins 0.000 claims abstract description 48
- 238000000034 method Methods 0.000 claims abstract description 24
- 150000001413 amino acids Chemical class 0.000 claims description 95
- 235000001014 amino acid Nutrition 0.000 claims description 89
- 229940024606 amino acid Drugs 0.000 claims description 88
- 210000004027 cell Anatomy 0.000 claims description 64
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 claims description 61
- 229960001230 asparagine Drugs 0.000 claims description 58
- 235000009582 asparagine Nutrition 0.000 claims description 58
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 claims description 55
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 claims description 51
- 235000003704 aspartic acid Nutrition 0.000 claims description 51
- 229960005261 aspartic acid Drugs 0.000 claims description 51
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 claims description 51
- 235000018102 proteins Nutrition 0.000 claims description 43
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 claims description 30
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 claims description 30
- 239000004473 Threonine Substances 0.000 claims description 30
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 30
- 229920001184 polypeptide Polymers 0.000 claims description 28
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 28
- 210000004899 c-terminal region Anatomy 0.000 claims description 21
- 108010076504 Protein Sorting Signals Proteins 0.000 claims description 20
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 claims description 18
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 claims description 18
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 claims description 18
- 238000013519 translation Methods 0.000 claims description 18
- 239000004474 valine Substances 0.000 claims description 18
- 229960004295 valine Drugs 0.000 claims description 18
- 235000014393 valine Nutrition 0.000 claims description 18
- 239000013598 vector Substances 0.000 claims description 16
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 claims description 15
- 210000002472 endoplasmic reticulum Anatomy 0.000 claims description 15
- 229960000310 isoleucine Drugs 0.000 claims description 15
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 claims description 15
- 235000014705 isoleucine Nutrition 0.000 claims description 15
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 claims description 12
- 101710091919 Eukaryotic translation initiation factor 4G Proteins 0.000 claims description 12
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 claims description 12
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 claims description 10
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 claims description 10
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 claims description 10
- 102100022692 Density-regulated protein Human genes 0.000 claims description 9
- 239000004471 Glycine Substances 0.000 claims description 9
- ONIBWKKTOPOVIA-BYPYZUCNSA-N L-Proline Chemical compound OC(=O)[C@@H]1CCCN1 ONIBWKKTOPOVIA-BYPYZUCNSA-N 0.000 claims description 9
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 claims description 9
- 102100040888 Malignant T-cell-amplified sequence 1 Human genes 0.000 claims description 9
- 101710120903 Malignant T-cell-amplified sequence 1 Proteins 0.000 claims description 9
- ONIBWKKTOPOVIA-UHFFFAOYSA-N Proline Natural products OC(=O)C1CCCN1 ONIBWKKTOPOVIA-UHFFFAOYSA-N 0.000 claims description 9
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 claims description 9
- 101710092028 Density-regulated protein Proteins 0.000 claims description 8
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 claims description 8
- 230000014759 maintenance of location Effects 0.000 claims description 8
- 229930182817 methionine Natural products 0.000 claims description 8
- 150000007523 nucleic acids Chemical class 0.000 claims description 8
- 210000003705 ribosome Anatomy 0.000 claims description 8
- 230000014621 translational initiation Effects 0.000 claims description 8
- 102100022823 Histone RNA hairpin-binding protein Human genes 0.000 claims description 7
- 101000825762 Homo sapiens Histone RNA hairpin-binding protein Proteins 0.000 claims description 7
- 210000004102 animal cell Anatomy 0.000 claims description 7
- 239000013604 expression vector Substances 0.000 claims description 7
- 108020004707 nucleic acids Proteins 0.000 claims description 7
- 102000039446 nucleic acids Human genes 0.000 claims description 7
- 101000653679 Homo sapiens Translationally-controlled tumor protein Proteins 0.000 claims description 6
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 claims description 6
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 claims description 6
- ZBZXYUYUUDZCNB-UHFFFAOYSA-N N-cyclohexa-1,3-dien-1-yl-N-phenyl-4-[4-(N-[4-[4-(N-[4-[4-(N-phenylanilino)phenyl]phenyl]anilino)phenyl]phenyl]anilino)phenyl]aniline Chemical compound C1=CCCC(N(C=2C=CC=CC=2)C=2C=CC(=CC=2)C=2C=CC(=CC=2)N(C=2C=CC=CC=2)C=2C=CC(=CC=2)C=2C=CC(=CC=2)N(C=2C=CC=CC=2)C=2C=CC(=CC=2)C=2C=CC(=CC=2)N(C=2C=CC=CC=2)C=2C=CC=CC=2)=C1 ZBZXYUYUUDZCNB-UHFFFAOYSA-N 0.000 claims description 6
- 102100029887 Translationally-controlled tumor protein Human genes 0.000 claims description 6
- 239000012528 membrane Substances 0.000 claims description 6
- 101001082110 Acanthamoeba polyphaga mimivirus Eukaryotic translation initiation factor 4E homolog Proteins 0.000 claims description 5
- 229930024421 Adenine Natural products 0.000 claims description 5
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 claims description 5
- 101001082109 Danio rerio Eukaryotic translation initiation factor 4E-1B Proteins 0.000 claims description 5
- 102100026900 Signal recognition particle receptor subunit alpha Human genes 0.000 claims description 5
- 101710126382 Signal recognition particle receptor subunit alpha Proteins 0.000 claims description 5
- 101710111458 Signal recognition particle receptor subunit alpha homolog Proteins 0.000 claims description 5
- 102100026231 Translocon-associated protein subunit alpha Human genes 0.000 claims description 5
- 101710112880 Translocon-associated protein subunit alpha Proteins 0.000 claims description 5
- 229960000643 adenine Drugs 0.000 claims description 5
- 229940104302 cytosine Drugs 0.000 claims description 5
- 229940035893 uracil Drugs 0.000 claims description 5
- 101150004109 CYB5R3 gene Proteins 0.000 claims description 4
- 101001093116 Homo sapiens Protein transport protein Sec61 subunit beta Proteins 0.000 claims description 4
- 102100036308 Protein transport protein Sec61 subunit beta Human genes 0.000 claims description 4
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 claims description 3
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 claims description 3
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 claims description 3
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 claims description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 claims description 3
- 239000004472 Lysine Substances 0.000 claims description 3
- 235000013922 glutamic acid Nutrition 0.000 claims description 3
- 239000004220 glutamic acid Substances 0.000 claims description 3
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 claims description 3
- 210000003527 eukaryotic cell Anatomy 0.000 claims description 2
- 210000005260 human cell Anatomy 0.000 claims description 2
- 230000001939 inductive effect Effects 0.000 claims description 2
- 101001044612 Homo sapiens Density-regulated protein Proteins 0.000 claims 1
- 101100030365 Arabidopsis thaliana CRR4 gene Proteins 0.000 description 30
- 239000013612 plasmid Substances 0.000 description 30
- 230000004927 fusion Effects 0.000 description 24
- 230000014616 translation Effects 0.000 description 19
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 13
- 239000012636 effector Substances 0.000 description 13
- 108090000331 Firefly luciferases Proteins 0.000 description 12
- 108010052090 Renilla Luciferases Proteins 0.000 description 12
- 238000002474 experimental method Methods 0.000 description 12
- 238000001890 transfection Methods 0.000 description 10
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 8
- 238000003556 assay Methods 0.000 description 8
- 239000012091 fetal bovine serum Substances 0.000 description 8
- FAPWRFPIFSIZLT-UHFFFAOYSA-M sodium chloride Inorganic materials [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 7
- 108020004414 DNA Proteins 0.000 description 6
- 210000004748 cultured cell Anatomy 0.000 description 6
- 230000000694 effects Effects 0.000 description 6
- 238000003670 luciferase enzyme activity assay Methods 0.000 description 6
- 238000004020 luminiscence type Methods 0.000 description 6
- 239000000243 solution Substances 0.000 description 6
- 239000002609 medium Substances 0.000 description 5
- 239000011780 sodium chloride Substances 0.000 description 5
- 241000196324 Embryophyta Species 0.000 description 4
- 108091028043 Nucleic acid sequence Proteins 0.000 description 4
- 238000004113 cell culture Methods 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 239000012096 transfection reagent Substances 0.000 description 4
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 108700026244 Open Reading Frames Proteins 0.000 description 3
- 230000004570 RNA-binding Effects 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 239000000203 mixture Substances 0.000 description 3
- 239000002953 phosphate buffered saline Substances 0.000 description 3
- 239000006228 supernatant Substances 0.000 description 3
- 238000012546 transfer Methods 0.000 description 3
- 108020003589 5' Untranslated Regions Proteins 0.000 description 2
- STRZQWQNZQMHQR-UAKXSSHOSA-N 5-fluorocytidine Chemical compound C1=C(F)C(N)=NC(=O)N1[C@H]1[C@H](O)[C@H](O)[C@@H](CO)O1 STRZQWQNZQMHQR-UAKXSSHOSA-N 0.000 description 2
- 102100022299 All trans-polyprenyl-diphosphate synthase PDSS1 Human genes 0.000 description 2
- 101710093939 All trans-polyprenyl-diphosphate synthase PDSS1 Proteins 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000206602 Eukaryota Species 0.000 description 2
- 108010014863 Eukaryotic Initiation Factors Proteins 0.000 description 2
- 102000002241 Eukaryotic Initiation Factors Human genes 0.000 description 2
- 108060001084 Luciferase Proteins 0.000 description 2
- 108700008625 Reporter Genes Proteins 0.000 description 2
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 2
- 108010017070 Zinc Finger Nucleases Proteins 0.000 description 2
- 230000004913 activation Effects 0.000 description 2
- 239000012190 activator Substances 0.000 description 2
- 230000010261 cell growth Effects 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 235000021186 dishes Nutrition 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- 230000006872 improvement Effects 0.000 description 2
- 239000007788 liquid Substances 0.000 description 2
- WLLRHFOXFKWDMQ-UHFFFAOYSA-N n,n'-bis(4'-diphenylamino-4-biphenylyl)-n,n'-diphenylbenzidine Chemical compound C1=CC=CC=C1N(C=1C=CC(=CC=1)C=1C=CC(=CC=1)N(C=1C=CC=CC=1)C=1C=CC(=CC=1)C=1C=CC(=CC=1)N(C=1C=CC=CC=1)C=1C=CC(=CC=1)C=1C=CC(=CC=1)N(C=1C=CC=CC=1)C=1C=CC=CC=1)C1=CC=CC=C1 WLLRHFOXFKWDMQ-UHFFFAOYSA-N 0.000 description 2
- 238000001243 protein synthesis Methods 0.000 description 2
- 239000000126 substance Substances 0.000 description 2
- 239000011701 zinc Substances 0.000 description 2
- 229910052725 zinc Inorganic materials 0.000 description 2
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 108700040094 Arabidopsis pentatricopeptide repeat Proteins 0.000 description 1
- 241000219195 Arabidopsis thaliana Species 0.000 description 1
- 241000283690 Bos taurus Species 0.000 description 1
- 241000282465 Canis Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- 241000282693 Cercopithecidae Species 0.000 description 1
- 101100007328 Cocos nucifera COS-1 gene Proteins 0.000 description 1
- 241000699800 Cricetinae Species 0.000 description 1
- 241000699802 Cricetulus griseus Species 0.000 description 1
- 102100036876 Cyclin-K Human genes 0.000 description 1
- 241000701022 Cytomegalovirus Species 0.000 description 1
- KCXVZYZYPLLWCC-UHFFFAOYSA-N EDTA Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(O)=O)CC(O)=O KCXVZYZYPLLWCC-UHFFFAOYSA-N 0.000 description 1
- 241000283086 Equidae Species 0.000 description 1
- 241000282326 Felis catus Species 0.000 description 1
- 108700007698 Genetic Terminator Regions Proteins 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- 102100036263 Glutamyl-tRNA(Gln) amidotransferase subunit C, mitochondrial Human genes 0.000 description 1
- 241000282412 Homo Species 0.000 description 1
- 101000713127 Homo sapiens Cyclin-K Proteins 0.000 description 1
- 101001001786 Homo sapiens Glutamyl-tRNA(Gln) amidotransferase subunit C, mitochondrial Proteins 0.000 description 1
- 101000998623 Homo sapiens NADH-cytochrome b5 reductase 3 Proteins 0.000 description 1
- 101710128836 Large T antigen Proteins 0.000 description 1
- 240000006240 Linum usitatissimum Species 0.000 description 1
- 235000004431 Linum usitatissimum Nutrition 0.000 description 1
- 239000005089 Luciferase Substances 0.000 description 1
- 101800000695 MLL cleavage product C180 Proteins 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 241000699670 Mus sp. Species 0.000 description 1
- 102100033153 NADH-cytochrome b5 reductase 3 Human genes 0.000 description 1
- 229920002274 Nalgene Polymers 0.000 description 1
- 101000853344 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) 60S ribosomal protein L5 Proteins 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 240000007594 Oryza sativa Species 0.000 description 1
- 235000007164 Oryza sativa Nutrition 0.000 description 1
- 108090000854 Oxidoreductases Proteins 0.000 description 1
- 108010044843 Peptide Initiation Factors Proteins 0.000 description 1
- 102000005877 Peptide Initiation Factors Human genes 0.000 description 1
- 241000219000 Populus Species 0.000 description 1
- 241000700159 Rattus Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 241000282887 Suidae Species 0.000 description 1
- 108010073062 Transcription Activator-Like Effectors Proteins 0.000 description 1
- 230000001464 adherent effect Effects 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 238000004458 analytical method Methods 0.000 description 1
- 108010006025 bovine growth hormone Proteins 0.000 description 1
- 239000000872 buffer Substances 0.000 description 1
- 238000004364 calculation method Methods 0.000 description 1
- 238000011109 contamination Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 238000005138 cryopreservation Methods 0.000 description 1
- 238000012258 culturing Methods 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 1
- 230000009977 dual effect Effects 0.000 description 1
- 230000002708 enhancing effect Effects 0.000 description 1
- 230000001605 fetal effect Effects 0.000 description 1
- 238000007710 freezing Methods 0.000 description 1
- 230000008014 freezing Effects 0.000 description 1
- 239000011521 glass Substances 0.000 description 1
- 239000008103 glucose Substances 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 238000001727 in vivo Methods 0.000 description 1
- 238000003780 insertion Methods 0.000 description 1
- 230000037431 insertion Effects 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 210000003292 kidney cell Anatomy 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000000813 microbial effect Effects 0.000 description 1
- 244000005700 microbiome Species 0.000 description 1
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- 102000044158 nucleic acid binding protein Human genes 0.000 description 1
- 108700020942 nucleic acid binding protein Proteins 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 210000001672 ovary Anatomy 0.000 description 1
- 229920000729 poly(L-lysine) polymer Polymers 0.000 description 1
- 230000008488 polyadenylation Effects 0.000 description 1
- 230000004481 post-translational protein modification Effects 0.000 description 1
- 230000001124 posttranscriptional effect Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 239000000047 product Substances 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 102000036115 ribosome binding proteins Human genes 0.000 description 1
- 108091000326 ribosome binding proteins Proteins 0.000 description 1
- 235000009566 rice Nutrition 0.000 description 1
- 238000010079 rubber tapping Methods 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 230000001954 sterilising effect Effects 0.000 description 1
- 238000004659 sterilization and disinfection Methods 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 238000004114 suspension culture Methods 0.000 description 1
- 238000013518 transcription Methods 0.000 description 1
- 230000035897 transcription Effects 0.000 description 1
- 230000001052 transient effect Effects 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 210000003501 vero cell Anatomy 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
Images






Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/415—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from plants
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
Definitions
- the present invention relates to a fusion protein for improving the protein expression level from a target mRNA.
- Zinc finger nuclease ZFN
- TALEN TAL Effector Nuclease
- Crispr-cas9 etc. are known as techniques using protein factors that act on DNA, but protein factors that act specifically on RNA were used. Technology development is still limited.
- PPR protein protein having a pentatripeptide repeat (PPR) motif
- PPR pentatripeptide repeat
- Patent Document 1 an amino acid that functions when the PPR motif exerts RNA binding properties is identified, and the relationship between the structure of the PPR motif and the target base has been clarified. It was possible to construct a protein having a PPR motif capable of binding to the RNA having it. However, a method for actually controlling a target RNA using the technique described in Patent Document 1 has not been found so far.
- the present inventors have found that a fusion protein of a predetermined functional domain and the PPR protein is capable of expressing the protein from the target mRNA.
- the inventors have found that the amount can be improved and have completed the present invention.
- the present invention in one embodiment, is a fusion protein for improving the protein expression level from the target mRNA
- the fusion protein is (A) one or a plurality of functional domains that improve protein expression from mRNA, and (B) a polypeptide portion that can bind to a target mRNA in an RNA base-selective or RNA base sequence-specific manner, Including
- the polypeptide part (B) is a polypeptide part comprising at least one PPR motif consisting of a 30-38 amino acid polypeptide represented by Formula 1 (Where: Helix A is a 12 amino acid long portion capable of forming an ⁇ -helix structure, and is represented by Formula 2.
- a 1 to A 12 each independently represent an amino acid; X is absent or is a moiety consisting of 1 to 9 amino acids in length; Helix B is a part capable of forming an ⁇ -helix structure consisting of 11 to 13 amino acids in length; L is a moiety represented by Formula 3 that is 2 to 7 amino acids long;
- each amino acid is numbered from the C-terminal side as “i” ( ⁇ 1), “ii” ( ⁇ 2), However, L iii to L vii may not exist.
- a combination of three amino acids of A 1 , A 4 and L ii , or a combination of two amino acids of A 4 and L ii corresponds to the base or base sequence of the target mRNA, Fusion protein.
- the polypeptide part (B) includes 2 to 30 PPR motifs, and the plurality of PPR motifs specifically bind to a base sequence of a target mRNA. It is characterized by being arranged in.
- the polypeptide part (B) includes 5 to 25 PPR motifs.
- the functional domain (A) is bound to the N-terminal side and / or the C-terminal side of the polypeptide part (B).
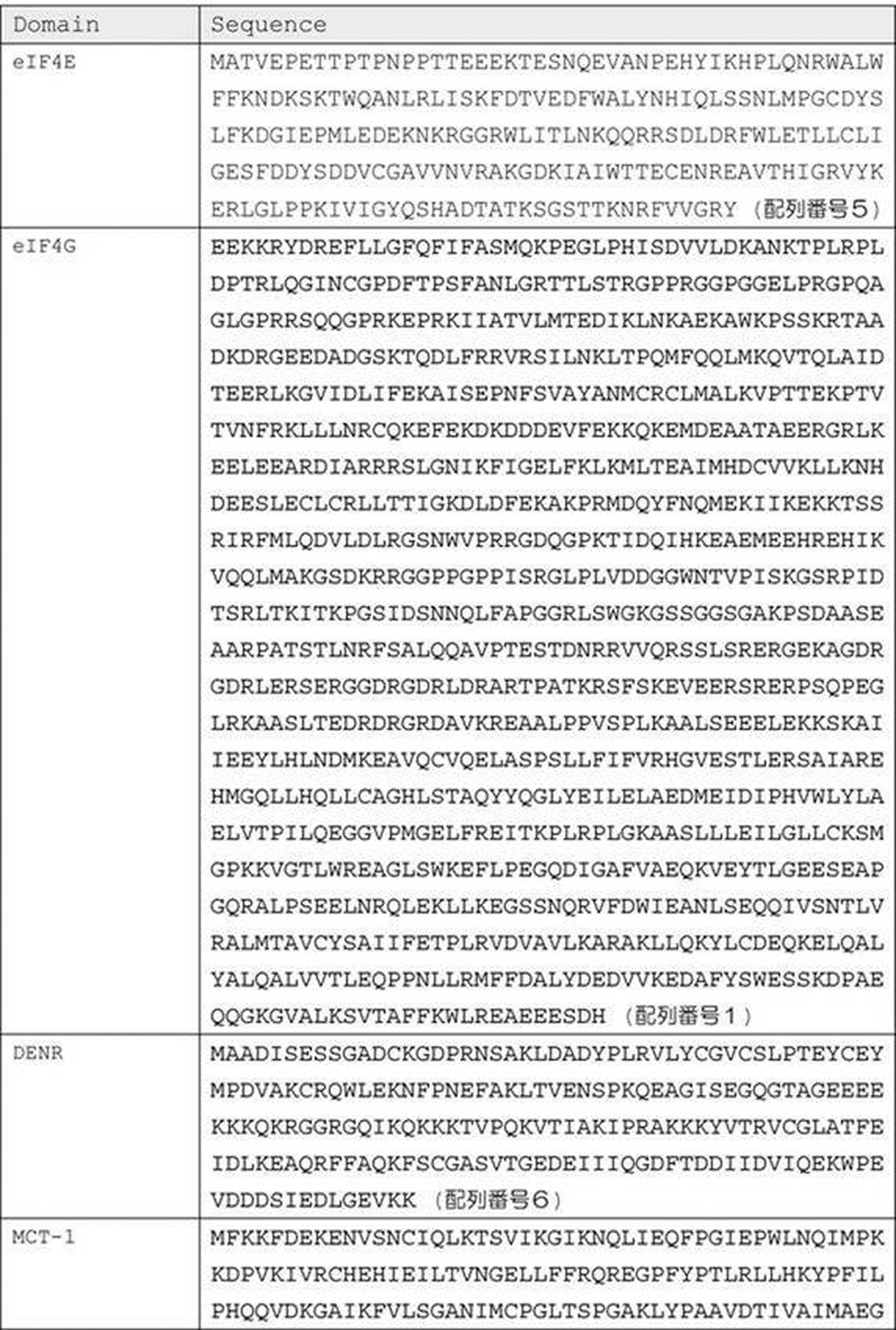
- the functional domain of (A) is related to a domain that induces ribosomes to mRNA, a domain that is related to mRNA translation initiation or promotion, and mRNA transport to the nucleus. It is selected from the group consisting of a domain, a domain related to binding to the endoplasmic reticulum membrane, a domain containing an ER retention signal sequence, and a domain containing an endoplasmic reticulum signal sequence.
- the domain that induces ribosomes to mRNA is a density-regulated protein (DENR), an MCT-1 (Malignant T-cell amplified sequence 1), or a TPT1 (Translationally-controlled).
- DER density-regulated protein
- MCT-1 Malignant T-cell amplified sequence 1
- TPT1 Translationally-controlled
- the domain involved in translation initiation or translation promotion of mRNA is a domain comprising all or a functional part of a polypeptide selected from the group consisting of eIF4E and eIF4G
- the domain related to transport of the mRNA to the outside of the nucleus is a domain containing all or a functional part of SLBP (Stem-loop binding protein);
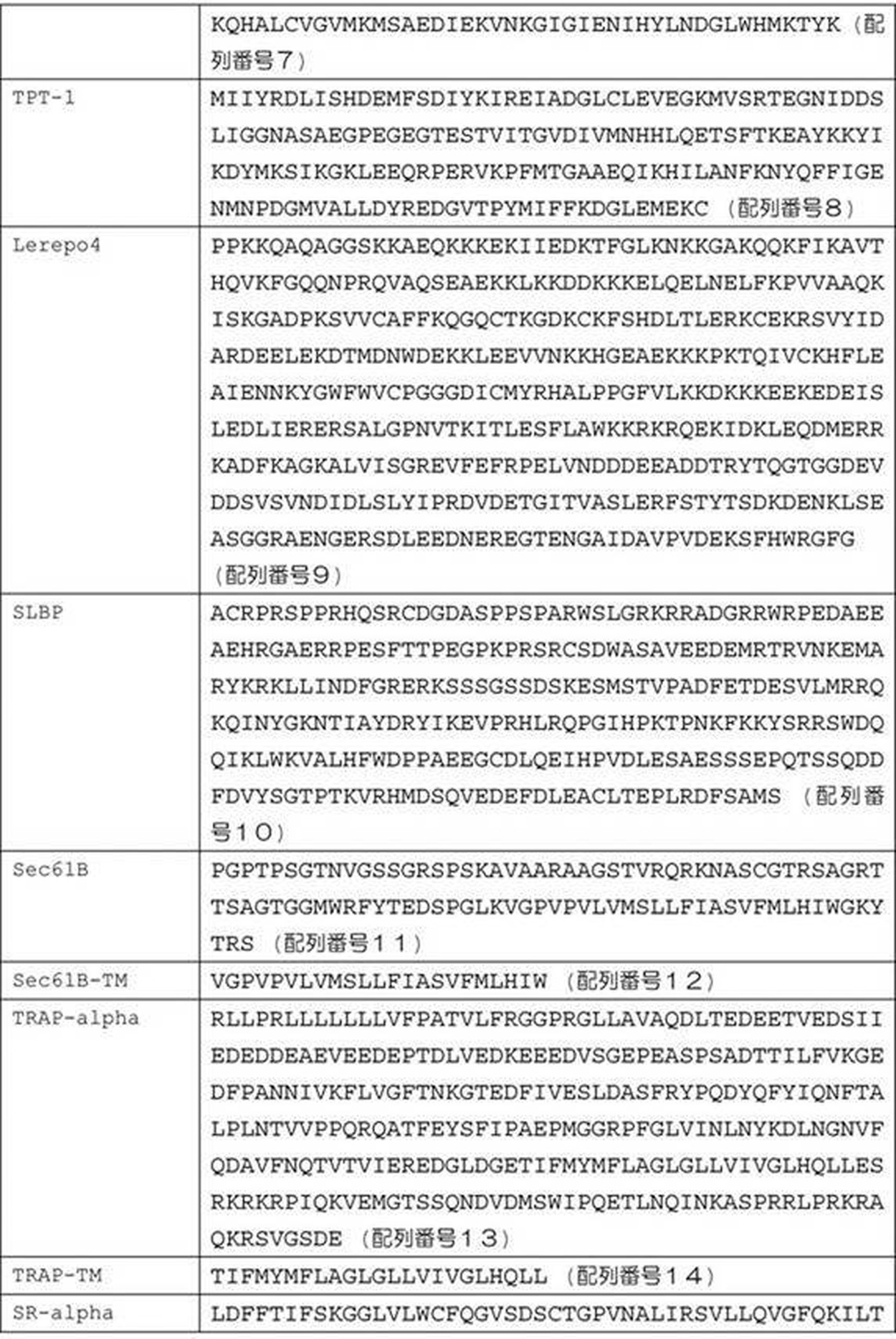
- the domain related to the binding to the endoplasmic reticulum membrane is a polypeptide selected from the group consisting of SEC61B, TRAP-alpha (Translocator associated protein alpha), SR-alpha, Dia1 (Cytochrom b5 reductase 3), and p180.
- the endoplasmic reticulum retention signal sequence is a signal sequence comprising a KDEL (KEEL) sequence, or
- the endoplasmic reticulum signal sequence is a signal sequence containing MGWSCIILFLVATATGAHS (SEQ ID NO: 22).
- a combination of three amino acids of A 1 , A 4 , and L ii in each of the above PPR motifs When bases targeted for PPR motif is A (adenine), a combination of three amino acids of A 1, A 4, and L ii is in the order of (A 1, A 4, L ii), ( valine , Threonine, asparagine), (phenylalanine, serine, asparagine), (phenylalanine, threonine, asparagine), (isoleucine, asparagine, aspartic acid), or (threonine, threonine, asparagine); When bases targeted for PPR motif is G (guanine), a combination of three amino acids of A 1, A 4, and L ii is in the order of (A 1, A 4, L ii), ( glutamic acid , Glycine, aspartic acid), (valine, threonine, aspartic acid), (lysine, threonine,
- the combination of two amino acids of A 4 and L ii in each of the aforementioned PPR motifs is as follows: When bases targeted for PPR motif is A (adenine), a combination of two amino acids of A 4 and L ii is in the order of (A 4, L ii), (threonine, asparagine), (Serine, asparagine) or (glycine, asparagine); When the target base of the PPR motif is G (guanine), the combination of the two amino acids A 4 and L ii is (A 4 , L ii ) in the order (threonine, aspartic acid).
- glycine, aspartic acid When bases targeted for PPR motif is U (uracil), a combination of two amino acids of A 4 and L ii is in the order of (A 4, L ii), (asparagine, aspartic acid), (proline , Aspartic acid), (methionine, aspartic acid), or (valine, threonine); When the target base of the PPR motif is C (cytosine), the combination of two amino acids of A 4 and L ii is (A 4 , L ii ) in the order (asparagine, asparagine), (Asparagine, serine) or (leucine, aspartic acid).
- the present invention also relates to a nucleic acid encoding the fusion protein of the present invention.
- the present invention relates to a vector (preferably an expression vector) containing the nucleic acid of the present invention.
- the present invention provides a method for improving the protein expression level from a target mRNA in a cell, Providing the fusion protein of the present invention as described above or the vector of the present invention as described above; and Introducing the fusion protein or vector into a cell, Method.
- the cell is a eukaryotic cell.
- the present invention is characterized in that the cell is an animal cell.
- the animal cell is a human cell.
- FIG. 1 shows a schematic diagram of an effector plasmid and a reporter plasmid used in Examples, and a schematic diagram of an experimental outline.
- FIG. 1A shows a schematic diagram of an effector plasmid and a reporter plasmid used in this Example. From the effector plasmid, a protein in which the PPR motif and eIF4G are fused is expressed. In this example, CRR4 protein, which has been well studied for target sequences, was used. From the reporter plasmid, Renilla luciferase (RLuc) and firefly luciferase (FLuc) are transcribed in the form of dicistronic mRNA.
- RLuc Renilla luciferase
- FLuc firefly luciferase
- FIG. 1B shows a schematic diagram of the experimental outline of this example.
- RLuc is translated at similar levels with or without PPR binding sequences. Therefore, the activity value of RLuc can be treated as a control for transfection with this reporter system.
- Translation of Fluc is initiated only when PPR-eIF4G binds to the PPR binding sequence and the translation factor can be attracted by the effect of eIF4G.
- FIG. 2 shows an experimental procedure for a reporter assay using HEK293T cells.
- FIG. 3 shows the experimental results of Example 1.
- FIG. 4 shows an outline of the experiment of Example 2.
- FIG. 5 shows the results of the experiment of Example 2 and explanation of the function of each domain.
- FIG. 6 shows the result of the experiment of Example 2 and the explanation of the function of each domain.
- PPR motif refers to the case where the E value obtained with PF01535 in Pfam and PS51375 in Prosite is less than a predetermined value when the amino acid sequence is analyzed with a protein domain search program on the Web, unless otherwise specified.
- the position number of the amino acid constituting the PPR motif defined in the present invention is almost the same as that of PF01535, but the number obtained by subtracting 2 from the amino acid position of PS51375 (eg, number 1 of the present invention ⁇ number 3 of PS51375) Equivalent to.
- the conserved amino acid sequence of the PPR motif has low conservation at the amino acid level, but the two ⁇ -helices are well conserved on the secondary structure.
- a typical PPR motif is composed of 35 amino acids, but its length is variable from 30 to 38 amino acids.
- the PPR motif referred to in the present invention consists of a polypeptide having a length of 30 to 38 amino acids represented by Formula 1.
- Helix A is a 12 amino acid long portion capable of forming an ⁇ -helix structure, and is represented by Formula 2.
- a 1 to A 12 each independently represent an amino acid;
- X is absent or is a moiety consisting of 1 to 9 amino acids in length;
- Helix B is a part capable of forming an ⁇ -helix structure consisting of 11 to 13 amino acids in length;
- L is a moiety represented by Formula 3 that is 2 to 7 amino acids long;
- each amino acid is numbered from the C-terminal side as “i” ( ⁇ 1), “ii” ( ⁇ 2), However, L iii to L vii may not exist.
- PPR protein refers to a PPR protein having one or more, preferably two or more PPR motifs, unless otherwise specified.
- protein refers to all substances consisting of polypeptides (chains in which a plurality of amino acids are peptide-bound) unless otherwise specified, and includes those consisting of relatively low molecular weight polypeptides.
- amino acid may refer to a normal amino acid molecule and may refer to an amino acid residue constituting a peptide chain. Which one is pointed out will be apparent to the skilled person from the context.
- the binding property of the PPR motif to the RNA base when it is referred to as “selective”, the binding activity to any one of the RNA bases is higher than the binding activity to other bases unless otherwise specified. It's expensive. This selectivity can be determined by a person skilled in the art by planning an experiment, and can also be obtained by calculation by a person skilled in the art.
- RNA base refers to a base of a ribonucleotide that constitutes RNA, unless otherwise specified.
- adenine (A), guanine (G), cytosine (C), or uracil ( U) PPR protein may have selectivity for bases in RNA, but does not bind to nucleic acid monomers.
- PPR protein is abundant in plants, and 500 proteins and about 5000 motifs can be found in Arabidopsis thaliana. There are also various PPR motifs and PPR proteins of various amino acid sequences in terrestrial plants such as rice, poplar, and flax.
- a PPR motif and a PPR protein that exist in nature may be used, or a PPR motif and a PPR protein designed based on the method disclosed in, for example, WO2013 / 058404 may be used.
- a desired PPR motif and PPR protein can be designed based on the following information disclosed in WO2013 / 058404.
- the present invention can utilize the knowledge regarding the combination of three amino acids A1, A4 and Lii and / or the combination of two amino acids A4 and Lii disclosed in WO2013 / 058404.
- the combination of the three amino acids A1, A4, and Lii is, in order, valine, asparagine, and aspartic acid.
- the PPR motif has a selective RNA base binding ability of binding strongly to U, then to C, and then to A or G.
- the combination of three amino acids A1, A4, and Lii is, in order, valine, threonine, and asparagine, the PPR motif binds strongly to A, then to G, then to C It has a selective RNA base binding ability that binds to but does not bind to U.
- PPR motif and PPR protein Identification and design: One PPR motif can recognize a specific base of RNA. Based on the present invention, it is possible to select or design a PPR motif selective for each of A, U, G, and C by making the amino acid at a specific position appropriate. A protein containing the appropriate sequence of can recognize the corresponding specific sequence. Furthermore, based on the above findings, a protein having a PPR motif that can selectively bind to a desired RNA base and a plurality of PPR motifs that can bind to a desired RNA in a sequence-specific manner can be designed. At the time of design, the sequence information of the natural PPR motif may be referred to for portions other than the amino acid at an important position in the PPR motif.
- the amino acid may be designed by substituting only the amino acids at the important positions.
- the number of repetitions of the PPR motif can be appropriately determined depending on the target sequence, but can be 2 or more, for example, 2 to 30.
- the PPR motif or PPR protein designed as described above can be prepared by methods well known to those skilled in the art. For example, from the designed PPR motif or PPR protein amino acid sequence, the nucleic acid sequence encoding it is determined and cloned to produce a transformant (expression vector, etc.) that produces the desired PPR motif or PPR protein. be able to.
- the present invention relates to the above-described PPR motif or PPR protein (that is, a polypeptide capable of binding to a target mRNA in an RNA base-selective or RNA base sequence-specific manner) and the protein expression level from the mRNA. It relates to a fusion protein with one or more functional domains to be improved.
- the “functional domain that improves the protein expression level from mRNA” that can be used in the present invention is, for example, all or a functional domain of a protein that is known to directly or indirectly promote translation of mRNA. It may be a functional part. More specifically, functional domains that can be used in the present invention include, for example, a domain that induces ribosomes to mRNA, a domain that is related to mRNA translation initiation or translation promotion, and a domain that is related to mRNA export to the nucleus. , A domain associated with binding to the endoplasmic reticulum membrane, a domain containing an ER retention signal sequence, or a domain containing an endoplasmic reticulum signal sequence.
- the domains for inducing ribosomes into the above mRNAs are: DENR (Density-regulated protein), MCT-1 (Malignant T-cell amplified sequence 1), TPT1 (Translationally-controlled pilot, and TPT1).
- DENR Density-regulated protein
- MCT-1 Malignant T-cell amplified sequence 1
- TPT1 Translationally-controlled pilot
- TPT1 Translationally-controlled pilot
- TPT1 Translationally-controlled pilot
- the domain related to the transport of mRNA to the outside of the nucleus may be a domain including all or a functional part of SLBP (Stem-loop binding protein).
- the domain related to the binding to the endoplasmic reticulum membrane is selected from the group consisting of SEC61B, TRAP-alpha (Translocated protein alpha), SR-alpha, Dia1 (Cytochrome b5 reductase 3), and p180. It may be a domain that contains all or part of a polypeptide.
- the endoplasmic reticulum retention signal (ER retention signal) sequence may be a signal sequence including a KDEL (KEEL) sequence.
- the endoplasmic reticulum signal sequence may be a signal sequence including MGWSCIILFLVATATGAHS (SEQ ID NO: 22).
- the functional domain may be fused to the N-terminal side of the PPR protein, may be fused to the C-terminal side, or may be fused to both the N-terminal side and the C-terminal side.
- the fusion protein of the present invention may contain a plurality of functional domains (for example, 2 to 5 functional domains).
- the functional domain and the PPR protein may be indirectly fused via a linker or the like.
- the present invention also relates to a nucleic acid encoding the fusion protein described above and a vector (for example, an expression vector) containing the nucleic acid.
- an expression vector means, for example, a vector comprising a DNA having a promoter sequence, a DNA encoding a desired protein, and a DNA having a terminator sequence from upstream, as long as the desired function is exhibited. They are not necessarily arranged in this order.
- various expression vectors commonly used by those skilled in the art can be used.
- the fusion protein of the present invention utilizes the eukaryotic RNA translation mechanism, it can function in cells of eukaryotes (eg, animals, plants, microorganisms (yeasts, etc.), protists).
- the fusion protein of the present invention can particularly function in an animal cell (in vitro or in vivo).
- animal cells into which the fusion protein of the present invention or a vector expressing the fusion protein of the present invention can be introduced include cells derived from humans, monkeys, pigs, cows, horses, dogs, cats, mice, and rats. be able to.
- cultured cells into which the fusion protein of the present invention or a vector expressing the fusion protein of the present invention can be introduced include, for example, Chinese hamster ovary (CHO) cells, COS-1 cells, COS-7 cells, VERO ( ATCC CCL-81) cells, BHK cells, canine kidney-derived MDCK cells, hamster AV-12-664 cells, HeLa cells, WI38 cells, 293 cells, 293T cells, PER. C6 cells can be mentioned, but are not limited thereto.
- Example 1 Improvement of protein expression level from target mRNA by fusion protein of PPR motif and eIF4G
- Cell culture HEK293T cell line
- Dulbecco's modified Eagle's medium DMEM, high glucose
- FBS Fetal bovine serum
- EDTA-NaCl solution 10 mM EDTA and 0.85% (w / v) NaCl, pH adjusted to 7.2-7.4, autoclaved, stored at room temperature 100 ⁇ 20 mm cell culture petri dish (Greiner bio one, Frickenhausen , Germany) ⁇ 10mL disposable sterile pipette ⁇ 15mL and 50mL plastic centrifuge tube ⁇ 1.8mL cryotube (Nunc; Thermo Fisher Scientific, Waltham, MA, USA) ⁇ Freeze container (Nalgene; Thermo Fisher Scientific, Waltham, MA, USA) ⁇ Banbanker (Lymphotec, Tokyo, Japan)
- the luciferase gene is inserted into the expression cassette, and the PPR binding sequence is inserted into its 5′-UTR (100 ng / ⁇ L) Poly-L-lysine coated 96-well plate (AGC Techno glass, Shizuoka, Japan) 1 ⁇ phosphate-buffered saline, PBS ( ⁇ ): 1.47 mM KH 2 PO 4 , 8.1 mM Na 2 HPO 4 , 137 mM NaCl, and 2.7 mM KCl.
- the reporter assay requires an effector plasmid and a reporter plasmid, both of which are constructed based on pcDNA3.1.
- the effector plasmid side contains a PPR protein and a fusion gene encoding a partial domain (SEQ ID NO: 1) of human eIF4G (FIG. 1A).
- CPR4 SEQ ID NO: 2 was used as the PPR protein portion.
- the reporter plasmid contains two open reading frames (ORF), Renilla luciferase (RLuc) and firefly luciferase (FLuc), which are transcribed dicistronically (FIG. 1A).
- the RLuc gene is located 5 ′ of the FLuc gene and was used as a control for gene expression.
- the PPR binding region is inserted into the 5'UTR of the FLuc ORF and from 3 repeats of the CRR4 recognition sequence (5'-UAUCUUGUCUUA-3 ') (SEQ ID NO: 3) interrupted by the 4-base sequence (ATCG and GATC) Obviously.
- the cytomegalovirus promoter (CMV) and the bovine growth hormone gene-derived polyadenylation signal were used for gene expression.
- an effector plasmid without eIF4G was constructed by fusing a FLAG epitope tag to PPR.
- a control reporter plasmid having no PPR binding region was constructed.
- FIG. 1 The outline of the procedure from cell culture to reporter assay in this example is depicted in FIG.
- Cell culture from frozen stock This process is performed aseptically. In advance, all instruments are disinfected with 70% ethanol. 1. Place 9 mL of DMEM medium in a 15 mL centrifuge tube (sterilized). 2. Thaw rapidly by incubating 1 mL of HEK293T frozen cells in a cryotube in a 37 ° C. water bath. 3. The cells are added to a 15 mL centrifuge tube containing 9 mL DMEM. 4). Centrifuge at 1100 ⁇ g for 2 minutes at room temperature and remove the supernatant. 5. The cells are resuspended in 10 mL DMEM (FBS added to a final concentration of 10%). 6).
- the suspended cells were transferred to a 100 mm petri dish.
- the petri dish was allowed to stand in an incubator under conditions of 37 ° C. and 5% CO 2 .
- the cultured cells were passaged after 24 hours.
- the cell density on the petri dish surface is maintained between 10% and 80%. Passaging is basically performed every 3 days (twice a week) or according to the cell growth rate. In addition, cells are re-cultured from frozen stock once a month to keep passage times low. Keeping passage times low and keeping cells healthy is important for efficient DNA transfection.
- Cell cryopreservation Frozen stocks are made using Bambanker reagent and ⁇ 50% cell density cultured cells in logarithmic growth. By using Bambanker, a high recovery rate and long-term storage can be easily performed. 1. The cells on the second day after passage are detached according to the passage procedure. Add 5-10 mL of DMEM and collect cells in a 50 mL centrifuge tube. 2. Centrifuge at 1100 ⁇ g for 2 minutes at room temperature and remove the supernatant. 3. Add 1 mL of Bambanker per petri dish and suspend. 4). Dispense the suspended cells quickly into a cryotube and close the lid. 5. Place in a special freeze container and let stand at -80 ° C for 12 hours (see note 7 ). 6). Transfer to a normal sample box and store at -80 ° C or in liquid nitrogen.
- Transient gene transfer Transfection
- 1. Before starting, prepare the required number of petri dishes containing the cells on the second day after passage and check whether the cells are healthy (see note 8 ). With a rough estimate, 96 assays can be performed in one dish. 2.
- the cells on the second day after passage are detached according to the passage procedure, and the suspended cells are transferred to a 50 mL centrifuge tube. 3. Centrifuge at 1100 ⁇ g for 2 minutes at room temperature and remove the supernatant. 4. Disperse the cell mass completely in 10 mL DMEM (FBS added to a final concentration of 10%). 5. The number of cells is counted using a hemocytometer and an inverted microscope.
- the dual luciferase assay is performed using the Dual-Glo Luciferase Assay System, following the manufacturer's instructions with minor modifications. 1. 24 hours after transfection, the medium of each well is replaced with 40 ⁇ L of 1 ⁇ PBS ( ⁇ ). 2. Add 40 ⁇ L of Dual-Glo luciferase reagent to each well and mix well by pipetting. 3. Allow to stand at room temperature for 10 minutes and transfer the entire volume to a 96-well luminometer plate. 4). Luminescence by firefly luciferase for FLuc gene expression is measured with a plate reader. 5. Dilute the Stop & Glo substrate 100-fold with Dual-Glo Stop & Glo buffer. Add 40 ⁇ L of the diluted solution to each well. 6). Let stand for at least 10 minutes at room temperature, then measure luminescence by Renilla luciferase for RLuc gene expression.
- FIG. 3 The results of the luciferase assay are shown in FIG. As shown in FIG. 3, a 2.75-fold translational activity was specifically observed in the presence of both PPR-eIF4G and a PPR binding sequence. That is, it was shown that a fusion protein of a PPR protein and a functional domain that improves the protein expression level from mRNA improves the protein expression level from the target mRNA.
- HEK293T is a human fetal kidney cell line expressing SV40 large T antigen. This cell line is easy to culture and can be transfected efficiently with various methods. HEK293T cells are available at RIKEN BRC (ja.brc.riken.jp) or ATCC (www.atcc.org).
- DMEM adds 1 ⁇ penicillin-streptomycin solution to avoid microbial contamination.
- the FBS is immobilized at 56 ° C for 30 minutes and stored at 4 ° C.
- Plasmid purity is critical to transfection efficiency. Plasmids should be isolated using transfection grade kits.
- the dedicated freeze container is a box with adjustable freezing speed (at -80 ° C, -1 ° C per minute), and can be stored frozen in a non-programmed -80 ° C freezer. is there. (Note 8) Use cells at a culture density of 50-80% for transfection. However, the appropriate cell density depends on the transfection reagent.
- transfection reagent ⁇ L
- plasmid DNA ⁇ g
- Example 2 Improvement of protein expression from target mRNA by fusion protein of PPR and other functional domains
- the final protein synthesis amount is determined by gene insertion position, mRNA transcription amount, post-transcriptional control (control at the RNA level), post-translational modification, and the like. Therefore, a method for enhancing translation of mRNA using the fact that PPR protein binds to a target RNA molecule in a sequence-specific manner was devised (FIG. 4).
- translation of mRNA is initiated by the translation initiation factor (eIF) intervening in the mRNA, and as a result, ribosomes are recruited near the translation initiation point.
- eIF translation initiation factor
- a reporter assay system using cultured animal cells was created (except that the functional domains used were different, and the experiment was performed in the same manner as described in Example 1). Performed).
- a system was constructed using a CRR4 protein (one of the Arabidopsis PPR proteins) known to bind to a specific RNA sequence (UAUCUUGUCUUUA) (SEQ ID NO: 3).
- CRR4 protein one of the Arabidopsis PPR proteins
- UAUCUUGUCUUUA SEQ ID NO: 3
- Candidate domains include (a) eIF proteins (eIF4E, eIF4G), (b) ribosome binding proteins (DENR, MCT-1, TPT1, Lelepo4), (c) Histon that facilitates transport of transcribed mRNA from the nucleus to the cytoplasm (DBP), (d) ER anchor protein (SEC61B, TRAP-alpha, SR-alpha, Dia1, p180), (e) ER retention signal (KDEL), (f) ER signal peptide .
- the fusion protein was cloned to be expressed in the form of HA-CRR4-XX or XX-CRR4-HA (HA: epitope tag (SEQ ID NO: 4); XX: candidate domain).
- the reporter plasmid was loaded with an expression cassette in which Renilla luciferase (RLuc) and firefly luciferase (Fluc) are transcribed in the form of dicistronic mRNA under the control of the CMV promoter.
- RLuc Renilla luciferase
- Fluc firefly luciferase
- Three PPR binding sequences UAUCUUGUCUUUA) (SEQ ID NO: 3) are inserted on the 5 ′ side of Fluc.
- the effector plasmid and the reporter plasmid were transfected into HEK293T cells, and the luminescence levels of RLUC and FLUC were measured.
- the RLUC luminescence amount was treated as a transfection control, and the FLUC luminescence amount / RLUC luminescence amount value was treated as a translational activity amount.
Abstract
Description
前記融合タンパク質は、
(A)mRNAからのタンパク質発現量を向上させる、1または複数の機能ドメイン、および
(B)標的mRNAに対してRNA塩基選択的に、または、RNA塩基配列特異的に結合可能なポリペプチド部分、
を含み、
前記(B)のポリペプチド部分が、式1で表される30~38アミノ酸長のポリペプチドからなるPPRモチーフを1個以上含む、ポリペプチド部分であり

Helix Aは、12アミノ酸長の、αヘリックス構造を形成可能な部分であって、式2で表され、
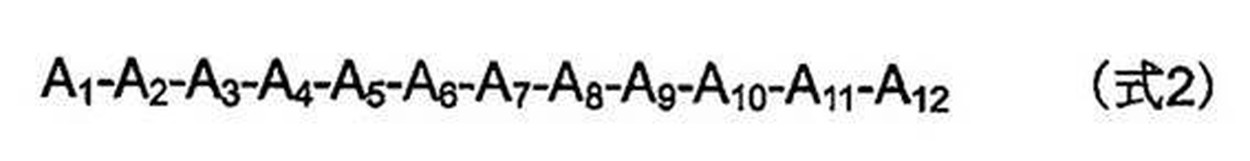
Xは、存在しないか、または、1~9アミノ酸長からなる部分であり;
Helix Bは、11~13アミノ酸長からなる、αヘリックス構造を形成可能な部分であり;
Lは、2~7アミノ酸長の、式3で表される部分であり;

ただし、Liii~Lviiは存在しない場合がある。)
A1、A4、及びLiiの3つのアミノ酸の組み合わせ、又はA4、Liiの2つのアミノ酸の組み合わせが、標的mRNAの塩基または塩基配列に対応したものとなっている、
融合タンパク質、に関する。
前記mRNAの翻訳開始または翻訳促進に関連するドメインが、eIF4EおよびeIF4Gからなる群から選択されるポリペプチドの全部または機能的な一部を含むドメインであり、
前記mRNAの核外への輸送に関連するドメインが、SLBP(Stem-loop binding protein)の全部または機能的な一部を含むドメインであり、
前記小胞体膜への結合に関連するドメインが、SEC61B、TRAP-alpha(Translocon associated protein alpha)、SR-alpha、Dia1(Cytochrome b5 reductase 3)、および、p180からなる群から選択されるポリペプチドの全部または機能的な一部を含むドメインであり、
前記小胞体保留シグナル(ER retention signal)配列は、KDEL(KEEL)配列を含むシグナル配列であり、または、
前記小胞体シグナル配列は、MGWSCIILFLVATATGAHS(配列番号22)を含むシグナル配列である、ことを特徴とする。
PPRモチーフの標的とする塩基がA(アデニン)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(バリン、トレオニン、アスパラギン)、(フェニルアラニン、セリン、アスパラギン)、(フェニルアラニン、トレオニン、アスパラギン)、(イソロイシン、アスパラギン、アスパラギン酸)、または(トレオニン、トレオニン、アスパラギン)であり;
PPRモチーフの標的とする塩基がG(グアニン)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(グルタミン酸、グリシン、アスパラギン酸)、(バリン、トレオニン、アスパラギン酸)、(リジン、トレオニン、アスパラギン酸)、または(ロイシン、トレオニン、アスパラギン酸)であり;
PPRモチーフの標的とする塩基がU(ウラシル)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(バリン、アスパラギン、アスパラギン酸)、(イソロイシン、アスパラギン、アスパラギン)、(イソロイシン、アスパラギン、アスパラギン酸)、(イソロイシン、メチオニン、アスパラギン酸)、(フェニルアラニン、プロリン、アスパラギン酸)、または(チロシン、プロリン、アスパラギン酸)であり;または、
PPRモチーフの標的とする塩基がC(シトシン)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(バリン、アスパラギン、アスパラギン)、(イソロイシン、アスパラギン、アスパラギン)、(バリン、アスパラギン、セリン)、または(イソロイシン、メチオニン、アスパラギン酸)である、ことを特徴とする。
PPRモチーフの標的とする塩基がA(アデニン)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(トレオニン、アスパラギン)、
(セリン、アスパラギン)、または(グリシン、アスパラギン)であり;
PPRモチーフの標的とする塩基がG(グアニン)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(トレオニン、アスパラギン酸)
または(グリシン、アスパラギン酸)であり;
PPRモチーフの標的とする塩基がU(ウラシル)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(アスパラギン、アスパラギン酸)、(プロリン、アスパラギン酸)、(メチオニン、アスパラギン酸)、または(バリン、トレオニン)であり;
PPRモチーフの標的とする塩基がC(シトシン)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(アスパラギン、アスパラギン)、
(アスパラギン、セリン)、または(ロイシン、アスパラギン酸)である、ことを特徴とする。
上記の本発明の融合タンパク質、または、上記の本発明のベクターを準備するステップ、および、
前記融合タンパク質、または、ベクターを細胞内へ導入するステップ、を含む、
方法、に関する。
本発明で「PPRモチーフ」というときは、特に記載した場合を除き、Web上のタンパク質ドメイン検索プログラムでアミノ酸配列を解析した際に、PfamにおいてPF01535、PrositeにおいてPS51375で得られるE値が所定値以下(望ましくはE-03)のアミノ酸配列をもつ30~38アミノ酸で構成されるポリペプチドをいう。本発明で定義するPPRモチーフを構成するアミノ酸の位置番号は、PF01535とほぼ同義である一方で、PS51375のアミノ酸の場所から2引いた数(例;本発明の1番→PS51375の3番)に相当する。ただし、“ii”(-2)番のアミノ酸というときは、PPRモチーフを構成するアミノ酸の後ろ(C末端側)から2番目のアミノ酸、又は次のPPRモチーフの1番アミノ酸に対して2コN末端側、すなわち-2番目のアミノ酸とする。次のPPRモチーフが明確に同定されない場合、次のヘリックス構造の1番目のアミノ酸に対して、2コ前のアミノ酸を“ii”とする。Pfamについてはhttp://pfam.sanger.ac.uk/、Prositeについては、http://www.expasy.org/prosite/を参照することができる。

Helix Aは、12アミノ酸長の、αヘリックス構造を形成可能な部分であって、式2で表され、

Xは、存在しないか、または、1~9アミノ酸長からなる部分であり;
Helix Bは、11~13アミノ酸長からなる、αヘリックス構造を形成可能な部分であり;
Lは、2~7アミノ酸長の、式3で表される部分であり;

ただし、Liii~Lviiは存在しない場合がある。
PPRモチーフの、1、4、“ii”(-1)番の3つのアミノ酸の組み合わせ(A1、A4、Lii)、又は4、“ii”(-1)番の2つのアミノ酸の組み合わせ(A4、Lii)が、RNA塩基との選択的な結合のために重要であり、これらの組み合わせにより、結合するRNA塩基がいずれであるかを決定できる。
(3-1)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、バリン、アスパラギン及びアスパラギン酸の場合、そのPPRモチーフは、Uに強く結合し、次にCに、その次にA又はGに対して結合するという、選択的なRNA塩基結合能を有する。
(3-2)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、バリン、トレオニン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合し、次にGに、その次にCに対して結合するが、Uには結合しないという、選択的なRNA塩基結合能を有する。
(3-3)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、バリン、アスパラギン、アスパラギンの場合、そのPPRモチーフは、Cに強く結合し、次にA又はUに対して結合するが、Gには結合しないという、選択的なRNA塩基結合能を有する。
(3-4)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、グルタミン酸、グリシン、アスパラギン酸の場合、そのPPRモチーフは、Gに強く結合するが、A、U及びCには結合しないという、選択的なRNA塩基結合能を有する。
(3-5)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、イソロイシン、アスパラギン、アスパラギンの場合、そのPPRモチーフは、Cに強く結合し、次にUに、その次にAに対して結合するが、Gには結合しないという、選択的なRNA塩基結合能を有する。
(3-6)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、バリン、トレオニン、アスパラギン酸の場合、そのPPRモチーフは、Gに強く結合し、次にUに対して結合するが、AとCには結合しないという、選択的なRNA塩基結合能を有する。
(3-7)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、リジン、トレオニン、アスパラギン酸、の場合、そのPPRモチーフは、Gに強く結合し、次にAに対して結合するが、U及びCには結合しないという、選択的なRNA塩基結合能を有する。
(3-8)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、フェニルアラニン、セリン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合し、次にCに、その次にG及びUに対して結合するという、選択的なRNA塩基結合能を有する。
(3-9)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、バリン、アスパラギン、セリンの場合、そのPPRモチーフは、Cに強く結合し、次にUに対して結合するが、A及びGには結合しないという、選択的なRNA塩基結合能を有する。
(3-10)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、フェニルアラニン、トレオニン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合するが、G、U及びCには結合しないという、選択的なRNA塩基結合能を有する。
(3-11)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、イソロイシン、アスパラギン、アスパラギン酸の場合、そのPPRモチーフは、Uに強く結合し、次にAに対して結合するが、G及びCには結合しないという、選択的なRNA塩基結合能を有する。
(3-12)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、トレオニン、トレオニン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合するが、G、U及びCには結合しないという、選択的なRNA塩基結合能を有する。
(3-13)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、イソロイシン、メチオニン、アスパラギン酸の場合、そのPPRモチーフは、Uに強く結合し、次にCに対して結合するが、A及びGには結合しないという、選択的なRNA塩基結合能を有する。
(3-14)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、フェニルアラニン、プロリン、アスパラギン酸の場合PPR、そのモチーフは、Uに強く結合し、次にCに対して結合するが、A及びGには結合しないという、選択的なRNA塩基結合能を有する。
(3-15)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、チロシン、プロリン、アスパラギン酸の場合、そのPPRモチーフは、Uに強く結合するが、A、G及びCには結合しないという、選択的なRNA塩基結合能を有する。
(3-16)A1、A4、及びLiiの3つのアミノ酸の組み合わせが、順に、ロイシン、トレオニン、アスパラギン酸の場合、そのPPRモチーフは、Gに強く結合するが、A、U及びCには結合しないという、選択的なRNA塩基結合能を有する。
(2-1)A4、Liiが、順に、アスパラギン、アスパラギン酸の場合、そのPPRモチーフは、Uに強く結合し、次にC、その次にA及びGに対して結合するという、選択的なRNA塩基結合能を有する。
(2-2)A4、Liiが、順に、アスパラギン、アスパラギンの場合、そのPPRモチーフは、Cに強く結合し、次にU、その次にA及びGに対して結合するという、選択的なRNA塩基結合能を有する。
(2-3)A4、Liiが、順に、トレオニン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合し、次にG、U及びCに対して弱く結合するという、選択的なRNA塩基結合能を有する。
(2-4)A4、Liiが、順に、トレオニン、アスパラギン酸の場合、そのPPRモチーフは、Gに強く結合し、次にA、U及びCに対して弱く結合するという、選択的なRNA塩基結合能を有する。
(2-5)A4、Liiが、順に、セリン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合し、次にG、U及びCに対して結合するという、選択的なRNA塩基結合能を有する。
(2-6)A4、Liiが、順に、グリシン、アスパラギン酸の場合、そのPPRモチーフは、Gに強く結合し、次にU、その次にAと結合するが、Cに結合しないという、選択的なRNA塩基結合能を有する。
(2-7)A4、Liiが、順に、アスパラギン、セリンの場合、そのPPRモチーフは、Cに強く結合し、次にU、その次にA及びGに対して結合するという、選択的なRNA塩基結合能を有する。
(2-8)A4、Liiが、順に、プロリン、アスパラギン酸の場合、そのPPRモチーフは、Uに強く結合し、次にG、C及びCに対して結合するが、Aに結合しないという、選択的なRNA塩基結合能を有する。
(2-9)A4、Liiが、順に、グリシン、アスパラギンの場合、そのPPRモチーフは、Aに強く結合し、次にGに対して結合するが、C及びUに結合しないという、選択的なRNA塩基結合能を有する。
(2-10)A4、Liiが、順に、メチオニン、アスパラギン酸の場合、そのPPRモチーフは、Uに強く結合し、次にA、G及びCに対して弱く結合するという、選択的なRNA塩基結合能を有する。
(2-11)A4、Liiが、順に、ロイシン、アスパラギン酸の場合、そのPPRモチーフは、Cに強く結合し、次にUに対して結合するが、A及びGに結合しないという、選択的なRNA塩基結合能を有する。
(2-12)A4、Liiが、順に、バリン、トレオニンの場合、そのPPRモチーフは、Uに強く結合し、次にAに対して結合するが、G及びCに結合しないという、選択的なRNA塩基結合能を有する。
同定および設計:
一のPPRモチーフは、RNAの特定の塩基を認識しうる。そして、本発明に基づけば、特定の位置のアミノ酸を適切にすることで、A、U、G、Cそれぞれに選択的なPPRモチーフを選択または設計することができ、さらにはそのようなPPRモチーフの適切な連続を含むタンパク質は、対応する特異的な配列を認識しうる。さらに、上述の知見により、所望のRNA塩基に選択的に結合可能なPPRモチーフ、および所望のRNAに配列特異的に結合可能な、複数個のPPRモチーフを有するタンパク質を設計することができる。設計に際し、PPRモチーフ中の重要な位置のアミノ酸以外の部分は、天然型のPPRモチーフの配列情報を参考にしてもよい。また、全体として天然型を用い、前記の重要な位置のアミノ酸だけを置換することにより、設計してもよい。PPRモチーフの繰り返し数は、標的配列に応じ、適宜とすることができるが、例えば2個以上とすることができ、2~30個とすることができる。
本発明は、上記に説明したPPRモチーフまたはPPRタンパク質(すなわち、標的mRNAに対してRNA塩基選択的に、または、RNA塩基配列特異的に結合可能なポリペプチド)と、mRNAからのタンパク質発現量を向上させる、1または複数の機能ドメインとの融合タンパク質に関する。
(装置)
・分子生物学実験のための基本的な施設(プラスミド構築のためなど)
・倒立顕微鏡(DM IL S40,Leica Microsystems,Wetzlar,Germany)
・CO2インキュベーター(KM-CC17RH2,Panasonic Healthcare,Tokyo,Japan)
・クリーンベンチ(MHE-S1300A2,Panasonic Healthcare,Tokyo,Japan)
・アスピレーター(SP-30,Air Liquide Medical Systems,Bovezzo BS,Italy)
・遠心機(スイングローター)(LC-200,Tomy Seiko,Tokyo,Japan)
・超低温フリーザー(-80°C)(MDF-C8V,Panasonic Healthcare,Tokyo,Japan)
・plateリーダー(EnSight Kaleido,PerkinElmer,Waltham,MA,USA)
・HEK293T細胞株(注釈1参照)
・Dulbecco’s modified Eagle’s培地(DMEM,高グルコース)(注釈2参照)
・100×penicillin-streptomycin溶液
・Fetal bovine serum(FBS)(注釈3参照)
・EDTA-NaCl溶液:10mM EDTA and 0.85%(w/v) NaCl、pHを7.2-7.4に調整、オートクレーブ滅菌、室温保存
・100×20mm細胞培養シャーレ(Greiner bio one,Frickenhausen,Germany)
・10mL使い捨て滅菌ピペット
・15mL and 50mL プラスチック遠沈管
・1.8mLクライオチューブ(Nunc;Thermo Fisher Scientific,Waltham,MA,USA)
・フリーズコンテナ(Nalgene;Thermo Fisher Scientific,Waltham,MA,USA)
・Bambanker(Lymphotec,Tokyo,Japan)
・エフェクタープラスミド:pcDNA3.1(Thermo Fisher Scientific,Waltham,MA,USA)を基本ベクターとして使用した。PPRとeIF4Gの融合遺伝子が発現カセットに挿入されている(100ng/μL)(注釈4参照)
・レポータープラスミド:pcDNA3.1(Thermo Fisher Scientific,Waltham,MA,USA)を基本ベクターとして使用した。ルシフェラーゼ遺伝子を発現カセットに挿入され、その5′-UTRにPPR結合配列が挿入されている(100ng/μL)
・Poly-L-lysineコーティングされた96-well plate(AGC Techno glass,Shizuoka,Japan)
・1×phosphate-buffered saline,PBS(-):1.47mM KH2PO4,8.1mM Na2HPO4,137mM NaCl,and 2.7mM KCl.pHを7.4に調整、オートクレーブ滅菌、室温保存
・血球計算盤(細胞数カウントのため)(Improved Neubauer Type Cell counter plate,Watson,Hyogo,Japan)
・トランスフェクション試薬(HilyMax,Dojindo Molecular Technologies,Kumamoto,Japan)
・Dual-Glo Luciferase Assay System(Promega,Madison,WI,USA.)
・96-well luminometer plate(PerkinElmer,Waltham,MA,USA).
(ベクター構築)
レポーターアッセイには、エフェクタープラスミドとレポータープラスミドが必要であり、両プラスミドともpcDNA3.1をもとに構築されている。エフェクタープラスミド側はPPRタンパク質と、ヒトeIF4Gの部分的なドメイン(配列番号1)をコードする融合遺伝子を含む(図1A)。PPRタンパク質部分は、CRR4(配列番号2)を用いた。レポータープラスミド側には、ウミシイタケルシフェラーゼ(RLuc)とホタルルシフェラーゼ(FLuc)という2つのオープンリーディングフレーム(ORF)を含んでおり、これらはジシストロニックに転写される(図1A)。RLuc遺伝子はFLuc遺伝子の5’側に位置しており、遺伝子発現のコントロールとして用いた。PPR結合領域はFLucのORFの5’UTRに挿入され、4塩基配列(ATCGとGATC)によって中断されるCRR4認識配列(5’-UAUCUUGUCUUUA-3’)(配列番号3)の3回の繰り返しからなる。エフェクター融合遺伝子、レポーター遺伝子ともに、それら遺伝子発現には、サイトメガロウイルスプロモーター(CMV)とウシ成長ホルモン遺伝子由来ポリアデニレーションシグナルが使用した。コントロール実験のために、eIF4Gを有しないエフェクタープラスミドを、PPRにFLAGエピトープタグを融合することで構築した。また、PPR結合領域を持たないコントロール用のレポータープラスミドを構築した。
本工程は無菌的に実施する。あらかじめ、全ての器具は70%エタノールで消毒する。
1.15mL遠沈管(滅菌済)に9mLのDMEM培地を入れる。
2.クライオチューブ内の1mLのHEK293T凍結細胞を37℃ウォーターバスでインキュベートすることによって、素早く融解する。
3.その細胞を9mLのDMEMを含んだ15mL遠沈管に加える。
4.室温で、1100×g 、2分間の遠心を行い、上清を取り除く。
5.その細胞を、10mLのDMEM(最終濃度が10%になるようにFBS を添加)に再懸濁する。
6.懸濁された細胞を100mmシャーレに移した。そのシャーレを37℃、5%CO2条件下のインキュベーターに静置した。凍結ストックから培養を始めた時は、その培養細胞は24時間後に継代した。
1.必要枚数の新しい100mmシャーレを準備する。8mLのDMEMと1mLのFBSを各シャーレにあらかじめ添加する。
2.培養細胞を含むシャーレ上の培地をアスピレーターで取り除く(注釈6参照)。
3.2mLのEDTA-NaCl溶液を、シャーレ内の表面の接着細胞上に、細胞を剥がさないように、優しく加える。シャーレを旋回させて溶液を満遍なく全体に行き渡らせる。EDTA-NaCl溶液をアスピレーターで取り除く。シャーレをタッピングして細胞を剥がす。
4.DMEM10mLをシャーレ内の細胞に加え、緩やかにピペッティングして懸濁する。
5.事前に準備された9mLの培地を含むシャーレに、各1mLの懸濁細胞(10%の培養細胞)を加える。シャーレを旋回させ、全体に細胞を行き渡らせる。
凍結ストックはBambanker試薬と、対数増殖中の~50%細胞密度の培養細胞を用いて作る。Bambankerの使用により、高回収率かつ長期保存が容易に可能となる。
1.継代後2日目の細胞を継代時の手順に従い、細胞を剥がす。5-10mLのDMEMを加え、50mLの遠沈管に細胞を回収する。
2.室温で、1100×g、2分間の遠心を行い、上清を取り除く。
3.1枚のシャーレあたり1mLのBambankerを加えて懸濁する。
4.懸濁細胞を素早くクライオチューブに分注し、蓋を閉める。
5.専用フリーズコンテナに入れ、-80℃で12時間静置する(注釈7参照)。
6.普通のサンプルボックスに移し、-80℃もしくは液体窒素内で保存する。
1.始める前に、継代後2日目の細胞を含むシャーレを、必要とされる枚数を準備し、その細胞が健全(正常)であるかを確かめる(注釈8参照)。おおよその見積りで、1枚のシャーレで96アッセイを行うことができる。
2.継代後2日目の細胞を継代時の手順に従い、細胞を剥がし、懸濁細胞を50mLの遠沈管に移す。
3.室温で、1100×g、2分間の遠心を行い、上清を取り除く。
4.10mLのDMEM(最終濃度が10%になるようにFBSを添加)内で、細胞塊を完全に分散させる。
5.血球計算盤と倒立顕微鏡を用いて、細胞数をカウントする。1-2×105個/mLになるように適量のDMEM(最終濃度が10%になるようにFBSを添加)内に懸濁する。
6.96-well plateを用意し、各wellあたり200μL(2-4×104個/mL)の懸濁培養細胞を加え、37℃、5%CO2条件下のインキュベーター内で一晩静置する。1wellが1アッセイに使用される。
7.翌日、各wellから慎重に培地を取り除き、100μLの新しいDMEM(最終濃度が10%になるようにFBSを添加)と交換する。
8.400ngのエフェクタープラスミド(100ng/μLを4μL)と100ngのレポータープラスミド(100ng/μLを1μL)を、新しい96-well PCR plate(もしくは0.2mLチューブ)上の単一well内に加える。
9.1アッセイあたり、1μLのHilyMAXを10μLの無血清DMEMで希釈する。
10.11μLの希釈溶液を、プラスミドを含む全てのwellに加える。ピペッティングでよく混合する。
11.室温で15分間静置する。培養細胞を含むwellに、全量の混合物を加える。37℃、5%CO2条件下のインキュベーター内で24時間静置する。
デュアルルシフェラーゼアッセイは、Dual-Glo Luciferase Assay Systemを使用して行われ、少しの変更点を除きメーカーの使用説明書に従って行う。
1.トランスフェクション24時間後、各wellの培地を、40μLの1×PBS(-)に交換する。
2.Dual-Glo luciferase試薬を、各wellに40μLずつ加え、ピペッティングでよく混合する。
3.室温で10分間静置し、全量を96-well luminometer plateに移す。
4.FLuc遺伝子発現に関するホタルルシフェラーゼによる発光をプレートリーダーで測定する。
5.Dual-Glo Stop&GloバッファーでStop&Glo基質を100倍希釈する。その希釈された溶液40μLを各wellに加える。
6.少なくとも室温で10分間静置し、それからRLuc遺伝子発現に関するウミシイタケルシフェラーゼによる発光を測定する。
1.アッセイ間のトランスフェクション効率の違いや実験誤差を補正するためにFLuc/RLuc値を計算する。
2.レポーター遺伝子発現の活性上昇を、PPR結合領域存在下、非存在下のそれぞれにおいて、本発明に係るプラスミド(CRR4と翻訳活性化ドメインeIF4Gとの融合タンパク質をコードするプラスミド)を用いて得られた実験値を、コントロールプラスミド(CRR4とFLAG-tagとの融合タンパク質をコードするプラスミド)を用いて得られた実験値で割り算することによって求める。
ルシフェラーゼアッセイの結果を図3に示した。図3に示すとおり、PPR-eIF4GとPPR結合配列の両方の存在下で特異的に2.75倍の翻訳活性が認められた。すなわち、PPRタンパク質と、mRNAからのタンパク質発現量を向上させる機能ドメインとの融合タンパク質は、標的mRNAからのタンパク質発現量を向上させることが示された。
(注釈1)HEK293Tは、SV40 large T antigen を発現しているヒト胎児由来腎臓細胞株である。この細胞株は培養が容易であり、様々な方法で高効率のトランスフェクションが可能である。HEK293T細胞はRIKEN BRC(ja.brc.riken.jp)もしくはATCC(www.atcc.org)で入手可能である。
(注釈2)DMEMは、微生物コンタミネーションを避けるために、1× penicillin-streptomycin溶液を添加する。
(注釈3)使用前に、FBSは56℃、30分間の非動化が行われ、4℃で保存する。
(注釈4)プラスミドの純度は、トランスフェクション効率に極めて重要である。プラスミドはトランスフェクショングレードのキットを用いることで単離すること。
(注釈5)日々の成長率が健全な細胞であることの指標となる。細胞の成長が抑制されることを回避するために、細胞は、常に十分なスペースと栄養条件下で培養すること。
(注釈6)HEK293T細胞は容易に培養シャーレから剥がれるので、培地を交換する際には、優しく扱うこと。
(注釈7)専用フリーズコンテナは凍結スピードを調節できる箱であり(-80℃で、およそ1分あたり-1℃)、そしてこれにより、非プログラム式の-80℃フリーザーでの凍結保存が可能である。
(注釈8)トランスフェクションに関して50-80%の培養密度での細胞を使用する。しかしながら、適切な細胞密度はトランスフェクション試薬に依存する。加えて、トランスフェクション試薬(μL)とプラスミドDNA(μg)の比率もメーカーの使用説明書に応じて、最適化するべきである。ここで記述された手順は、96-well plateで、HEK293T細胞、トランスフェクション試薬としてHilyMAXを用いた条件で最適化されている。
上記のアイデアを検証するために、動物培養細胞(HEK293T)を使ったレポーターアッセイシステムを作成した(用いた機能ドメインが異なること以外は、実施例1に記載の方法と同様の方法で実験を行った)。特定のRNA配列(UAUCUUGUCUUUA)(配列番号3)に結合することが分かっているCRR4タンパク質(シロイヌナズナPPRタンパク質の一つ)を使って系を構築した。まず、CRR4と候補タンパク質機能ドメインとの融合タンパク質発現ベクター(エフェクタープラスミド)を作成した。候補ドメインは、(a)eIFタンパク質(eIF4E,eIF4G)、(b)リボソーム結合タンパク質(DENR,MCT-1,TPT1,Lerepo4)、(c)転写されたmRNAの核から細胞質への輸送促進するHistonの翻訳制御因子(SLBP)、(d)ERアンカータンパク質(SEC61B,TRAP-alpha,SR-alpha,Dia1,p180)、(e)ER retention signal(KDEL)、(f)ER signal peptide、を選んだ。融合タンパク質は、HA-CRR4-XXもしくは、XX-CRR4-HAの形で発現するようにクローニングした(HA:エピトープタグ(配列番号4);XX:候補ドメイン)。
以下の(A)、(B)の指標を用いて、図5および図6に示す結果を検討した。
(A)標的非存在下と存在下との比較
配列特異的にどれくらい翻訳量変化があったのかが分かる。
(B)標的存在下、エフェクターなし(empty)と比較(黒色破線)
ドメイン付加による翻訳量変化が分かる。
(A)2.7倍
(B)1.6倍
2.CRR4のC末側にeIF4Gを融合
(A)4.5倍
(B)3.3倍
3.CRR4のN末側にDENRを融合
(A)1.7倍
(B)1.3倍
4.CRR4のC末側にDENRを融合
(A)2.4倍
(B)1.7倍
5.CRR4のN末側にMCT-1を融合
(A)1.3倍
(B)1.0倍
6.CRR4のC末側にMCT-1を融合
(A)2.0倍
(B)1.2倍
7.CRR4のN末側にTPT-1を融合
(A)1.4倍
(B)1.0倍
8.CRR4のC末側にTPT-1を融合
(A)2.4倍
(B)1.9倍
9.CRR4のN末側にLerepo 4を融合
(A)3.0倍
(B)1.8倍
10.CRR4のC末側にLerepo 4を融合
(A)3.3倍
(B)2.6倍
11.CRR4のC末側にSLBPを融合
(A)4.1倍
(B)3.3倍
12.CRR4のC末側にSec61Bを融合
(A)1.6倍
(B)1.6倍
13.CRR4のC末側にSec61BTMを融合
(A)2.4倍
(B)1.9倍
14.CRR4のC末側にTRAP‐alphaを融合
(A)3.5倍
(B)4.5倍
15.CRR4のC末側にTRAPTMを融合
(A)2.3倍
(B)1.6倍
16.CRR4のN末側にSR‐alphaを融合
(A)1.7倍
(B)1.5倍
17.CRR4のN末側にDia1TMを融合
(A)1.8倍
(B)1.2倍
18.CRR4のN末側にP180TM2Rを融合
(A)2.1倍
(B)1.5倍
19.CRR4のN末側にP180TMHを融合
(A)2.3倍
(B)2.5倍
20.CRR4のN末側にP180TM2を融合
(A)3.0倍
(B)2.1倍
21.CRR4のC末側にKDELを融合
(A)1.8倍
(B)1.4倍
22.CRR4のC末側にKEELを融合
(A)2.3倍
(B)2.1倍
23.CRR4のN末側にSignal peptide(SP)を融合
(A)1.4倍
(B)2.0倍

Claims (15)
- 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質であって、
前記融合タンパク質は、
(A)mRNAからのタンパク質発現量を向上させる、1または複数の機能ドメイン、および
(B)標的mRNAに対してRNA塩基選択的に、または、RNA塩基配列特異的に結合可能なポリペプチド部分、
を含み、
前記(B)のポリペプチド部分が、式1で表される30~38アミノ酸長のポリペプチドからなるPPRモチーフを1個以上含む、ポリペプチド部分であり

Helix Aは、12アミノ酸長の、αヘリックス構造を形成可能な部分であって、式2で表され、
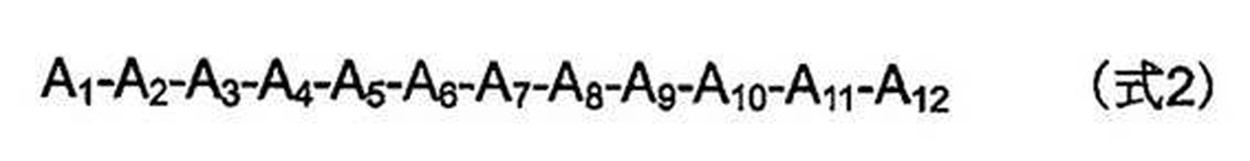
Xは、存在しないか、または、1~9アミノ酸長からなる部分であり;
Helix Bは、11~13アミノ酸長からなる、αヘリックス構造を形成可能な部分であり;
Lは、2~7アミノ酸長の、式3で表される部分であり;

ただし、Liii~Lviiは存在しない場合がある。)
A1、A4、及びLiiの3つのアミノ酸の組み合わせ、又はA4、Liiの2つのアミノ酸の組み合わせが、標的mRNAの塩基または塩基配列に対応したものとなっている、
融合タンパク質。 - 請求項1に記載の融合タンパク質であって、前記(B)のポリペプチド部分は、前記PPRモチーフを2~30個含み、前記複数のPPRモチーフが、標的mRNAの塩基配列に特異的に結合するように配置されている、
融合タンパク質。 - 請求項2に記載の融合タンパク質であって、前記(B)のポリペプチド部分は、前記PPRモチーフを5~25個含む、
融合タンパク質。 - 請求項1~3のいずれか1項に記載の融合タンパク質であって、前記(A)の機能ドメインは、前記(B)のポリペプチド部分のN末端側および/またはC末端側に結合されている、
融合タンパク質。 - 請求項1~4のいずれか1項に記載の融合タンパク質であって、前記(A)の機能ドメインが、mRNAへリボソームを誘導するドメイン、mRNAの翻訳開始または翻訳促進に関連するドメイン、mRNAの核外への輸送に関連するドメイン、小胞体膜への結合に関連するドメイン、小胞体保留シグナル(ER retention signal)配列を含むドメイン、および、小胞体シグナル配列を含むドメイン、からなる群から選択される、
融合タンパク質。 - 請求項5に記載の融合タンパク質であって、
前記mRNAへリボソームを誘導するドメインは、DENR(Density-regulated protein)、MCT-1(Malignant T-cell amplified sequence 1)、TPT1(Translationally-controlled tumor protein)、および、Lerepo4(Zinc finger CCCH-domain)からなる群から選択されるポリペプチドの全部または機能的な一部を含むドメインであり、
前記mRNAの翻訳開始または翻訳促進に関連するドメインは、eIF4EおよびeIF4Gからなる群から選択されるポリペプチドの全部または機能的な一部を含むドメインであり、
前記mRNAの核外への輸送に関連するドメインは、SLBP(Stem-loop binding protein)の全部または機能的な一部を含むドメインであり、
前記小胞体膜への結合に関連するドメインは、SEC61B、TRAP-alpha(Translocon associated protein alpha)、SR-alpha、Dia1(Cytochrome b5 reductase 3)、および、p180からなる群から選択されるポリペプチドの全部または機能的な一部を含むドメインであり、
前記小胞体保留シグナル(ER retention signal)配列は、KDEL(KEEL)配列を含むシグナル配列であり、または、
前記小胞体シグナル配列は、MGWSCIILFLVATATGAHSを含むシグナル配列である、
融合タンパク質。 - 請求項1~6のいずれか1項に記載の融合タンパク質であって、前記の各PPRモチーフにおけるA1、A4、およびLiiの3つのアミノ酸の組み合わせが;
PPRモチーフの標的とする塩基がA(アデニン)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(バリン、トレオニン、アスパラギン)、(フェニルアラニン、セリン、アスパラギン)、(フェニルアラニン、トレオニン、アスパラギン)、(イソロイシン、アスパラギン、アスパラギン酸)、または(トレオニン、トレオニン、アスパラギン)であり;
PPRモチーフの標的とする塩基がG(グアニン)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(グルタミン酸、グリシン、アスパラギン酸)、(バリン、トレオニン、アスパラギン酸)、(リジン、トレオニン、アスパラギン酸)、または(ロイシン、トレオニン、アスパラギン酸)であり;
PPRモチーフの標的とする塩基がU(ウラシル)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(バリン、アスパラギン、アスパラギン酸)、(イソロイシン、アスパラギン、アスパラギン)、(イソロイシン、アスパラギン、アスパラギン酸)、(イソロイシン、メチオニン、アスパラギン酸)、(フェニルアラニン、プロリン、アスパラギン酸)、または(チロシン、プロリン、アスパラギン酸)であり;または、
PPRモチーフの標的とする塩基がC(シトシン)である場合には、A1、A4、およびLiiの3つのアミノ酸の組み合わせが、(A1、A4、Lii)の順に、(バリン、アスパラギン、アスパラギン)、(イソロイシン、アスパラギン、アスパラギン)、(バリン、アスパラギン、セリン)、または(イソロイシン、メチオニン、アスパラギン酸)である、
融合タンパク質。 - 請求項1~6のいずれか1項に記載の融合タンパク質であって、前記の各PPRモチーフにおけるA4およびLiiの2つのアミノ酸の組み合わせが;
PPRモチーフの標的とする塩基がA(アデニン)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(トレオニン、アスパラギン)、
(セリン、アスパラギン)、または(グリシン、アスパラギン)であり;
PPRモチーフの標的とする塩基がG(グアニン)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(トレオニン、アスパラギン酸)
または(グリシン、アスパラギン酸)であり;
PPRモチーフの標的とする塩基がU(ウラシル)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(アスパラギン、アスパラギン酸)、(プロリン、アスパラギン酸)、(メチオニン、アスパラギン酸)、または(バリン、トレオニン)であり;
PPRモチーフの標的とする塩基がC(シトシン)である場合には、A4およびLiiの2つのアミノ酸の組み合わせが、(A4、Lii)の順に、(アスパラギン、アスパラギン)、
(アスパラギン、セリン)、または(ロイシン、アスパラギン酸)である、
融合タンパク質。 - 請求項1~8のいずれか1項に記載の融合タンパク質をコードする、核酸。
- 請求項9に記載の核酸を含む、ベクター。
- ベクターが発現ベクターである、請求項10に記載のベクター。
- 細胞内で標的mRNAからのタンパク質発現量を向上させる方法であって、
請求項1~8のいずれか1項に記載の融合タンパク質、または、請求項10または11に記載のベクターを準備するステップ、および、
前記融合タンパク質、または、ベクターを細胞内へ導入するステップ、を含む、
方法。 - 請求項12に記載の方法であって、
前記細胞が、真核生物の細胞である、
方法。 - 請求項13に記載の方法であって、
前記細胞が、動物細胞である、
方法。 - 請求項14に記載の発明であって、
前記動物細胞が、ヒト細胞である、
方法。
Priority Applications (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201780041619.9A CN109415446B (zh) | 2016-06-03 | 2017-05-30 | 用于提高靶mRNA的蛋白质表达水平的融合蛋白 |
| CA3026340A CA3026340A1 (en) | 2016-06-03 | 2017-05-30 | Fusion protein for improving protein expression level from target mrna |
| KR1020187037821A KR102407776B1 (ko) | 2016-06-03 | 2017-05-30 | 표적 mRNA로부터의 단백질 발현량을 향상시키기 위한 융합 단백질 |
| AU2017275184A AU2017275184B2 (en) | 2016-06-03 | 2017-05-30 | Fusion protein for improving protein expression from target mRNA |
| US16/305,080 US11136361B2 (en) | 2016-06-03 | 2017-05-30 | Fusion protein for improving protein expression from target mRNA |
| SG11201810606TA SG11201810606TA (en) | 2016-06-03 | 2017-05-30 | FUSION PROTEIN FOR IMPROVING PROTEIN EXPRESSION FROM TARGET mRNA |
| ES17806675T ES2874230T3 (es) | 2016-06-03 | 2017-05-30 | Proteína de fusión para mejorar la expresión de proteínas a partir de ARNm diana |
| DK17806675.9T DK3466978T3 (da) | 2016-06-03 | 2017-05-30 | Fusionsprotein til forbedring af proteinekspression fra mål-mRNA |
| JP2018520924A JP6928386B2 (ja) | 2016-06-03 | 2017-05-30 | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 |
| EP17806675.9A EP3466978B1 (en) | 2016-06-03 | 2017-05-30 | Fusion protein for improving protein expression from target mrna |
| BR112018075010-7A BR112018075010A2 (pt) | 2016-06-03 | 2017-05-30 | proteína de fusão para melhorar o nível de expressão de proteína a partir de rnam alvo |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201662345252P | 2016-06-03 | 2016-06-03 | |
| US62/345,252 | 2016-06-03 | ||
| JP2016120524 | 2016-06-17 | ||
| JP2016-120524 | 2016-06-17 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2017209122A1 true WO2017209122A1 (ja) | 2017-12-07 |
Family
ID=60478518
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/JP2017/020076 WO2017209122A1 (ja) | 2016-06-03 | 2017-05-30 | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 |
Country Status (5)
| Country | Link |
|---|---|
| KR (1) | KR102407776B1 (ja) |
| AU (1) | AU2017275184B2 (ja) |
| CA (1) | CA3026340A1 (ja) |
| SG (1) | SG11201810606TA (ja) |
| WO (1) | WO2017209122A1 (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020241877A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 凝集の少ないpprタンパク質及びその利用 |
| WO2020241876A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006217871A (ja) * | 2005-02-10 | 2006-08-24 | Tokyo Univ Of Science | 遺伝子の転写調節方法 |
| JP2009544296A (ja) * | 2006-07-21 | 2009-12-17 | サントル、ナショナール、ド、ラ、ルシェルシュ、シアンティフィク、(セーエヌエルエス) | バイオリアクター生産性を向上させるポジティブサイトモジュリン |
| WO2011111829A1 (ja) * | 2010-03-11 | 2011-09-15 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の改変方法 |
| WO2013058404A1 (ja) | 2011-10-21 | 2013-04-25 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 |
| WO2014175284A1 (ja) * | 2013-04-22 | 2014-10-30 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| JP2015221026A (ja) * | 2014-05-23 | 2015-12-10 | 公立大学法人名古屋市立大学 | 人工合成mRNAの翻訳効率化方法 |
-
2017
- 2017-05-30 WO PCT/JP2017/020076 patent/WO2017209122A1/ja unknown
- 2017-05-30 CA CA3026340A patent/CA3026340A1/en active Pending
- 2017-05-30 SG SG11201810606TA patent/SG11201810606TA/en unknown
- 2017-05-30 KR KR1020187037821A patent/KR102407776B1/ko active IP Right Grant
- 2017-05-30 AU AU2017275184A patent/AU2017275184B2/en active Active
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006217871A (ja) * | 2005-02-10 | 2006-08-24 | Tokyo Univ Of Science | 遺伝子の転写調節方法 |
| JP2009544296A (ja) * | 2006-07-21 | 2009-12-17 | サントル、ナショナール、ド、ラ、ルシェルシュ、シアンティフィク、(セーエヌエルエス) | バイオリアクター生産性を向上させるポジティブサイトモジュリン |
| WO2011111829A1 (ja) * | 2010-03-11 | 2011-09-15 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の改変方法 |
| WO2013058404A1 (ja) | 2011-10-21 | 2013-04-25 | 国立大学法人九州大学 | Pprモチーフを利用したrna結合性蛋白質の設計方法及びその利用 |
| WO2014175284A1 (ja) * | 2013-04-22 | 2014-10-30 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| JP2016039810A (ja) * | 2013-04-22 | 2016-03-24 | 国立大学法人九州大学 | Pprモチーフを利用したdna結合性タンパク質およびその利用 |
| JP2015221026A (ja) * | 2014-05-23 | 2015-12-10 | 公立大学法人名古屋市立大学 | 人工合成mRNAの翻訳効率化方法 |
Non-Patent Citations (1)
| Title |
|---|
| WOODSON J D ET AL.: "Coordination of gene expression between organellar and nuclear genomes", NATURE REVIEWS GENETICS, vol. 9, no. 5, May 2008 (2008-05-01), pages 383 - 395, XP055551958 * |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020241877A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 凝集の少ないpprタンパク質及びその利用 |
| WO2020241876A1 (ja) | 2019-05-29 | 2020-12-03 | エディットフォース株式会社 | 効率的なpprタンパク質の作製方法及びその利用 |
Also Published As
| Publication number | Publication date |
|---|---|
| SG11201810606TA (en) | 2018-12-28 |
| AU2017275184A1 (en) | 2018-12-13 |
| AU2017275184B2 (en) | 2021-05-06 |
| CA3026340A1 (en) | 2017-12-07 |
| KR20190015374A (ko) | 2019-02-13 |
| KR102407776B1 (ko) | 2022-06-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Budiman et al. | Eukaryotic initiation factor 4a3 is a selenium-regulated RNA-binding protein that selectively inhibits selenocysteine incorporation | |
| Majumder et al. | The hnRNA-binding proteins hnRNP L and PTB are required for efficient translation of the Cat-1 arginine/lysine transporter mRNA during amino acid starvation | |
| Fritz et al. | RNA-binding protein RBMS3 is expressed in activated hepatic stellate cells and liver fibrosis and increases expression of transcription factor Prx1 | |
| Rozanska et al. | The human RNA-binding protein RBFA promotes the maturation of the mitochondrial ribosome | |
| BR112016013443B1 (pt) | Métodos para produzir de forma recombinante um produto de interesse, para produção de uma célula hospedeira eucariótica para produzir de forma recombinante um produto de interesse, e para analisar as células eucarióticas quanto à sua adequabilidade como células hospedeiras para expressão recombinante de um produto de interesse | |
| Roithová et al. | The Sm-core mediates the retention of partially-assembled spliceosomal snRNPs in Cajal bodies until their full maturation | |
| JP5143552B2 (ja) | 細胞周期フェーズマーカー | |
| US7157571B2 (en) | Hepatoma specific chimeric regulatory sequence | |
| WO2017209122A1 (ja) | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 | |
| Roder et al. | NF-Y binds to the inverted CCAAT box, an essential element for cAMP-dependent regulation of the rat fatty acid synthase (FAS) gene | |
| Kim et al. | Proline-rich transcript in brain protein induces stress granule formation | |
| JP6928386B2 (ja) | 標的mRNAからのタンパク質発現量を向上させるための融合タンパク質 | |
| JP5858393B2 (ja) | 抗体の可変領域を用いた新規な遺伝子発現調節方法 | |
| CN112111490B (zh) | 一种可视化活细胞中内源性低丰度单分子rna的方法及应用 | |
| Long et al. | RNAe in a transgenic growth hormone mouse model shows potential for use in gene therapy | |
| Liu et al. | Subscaling of a cytosolic RNA binding protein governs cell size homeostasis in the multiple fission alga Chlamydomonas | |
| Kobayashi et al. | Development of genome engineering tools from plant-specific PPR proteins using animal cultured cells | |
| CN107034219B (zh) | 一种gata2蛋白可结合dna片段及在gata2活性检测中的应用 | |
| US20130023643A1 (en) | Nuclear localization signal peptides derived from vp2 protein of chicken anemia virus and uses of said peptides | |
| Geng et al. | Two methods for improved purification of full-length mammalian proteins that have poor expression and/or solubility using standard Escherichia coli procedures | |
| US20240093206A1 (en) | System of stable gene expression in cell lines and methods of making and using the same | |
| Crncec et al. | Degron tagging using mAID and SMASh tags in RPE-1 cells | |
| CN107365770B (zh) | 针对自噬相关基因Beclin1编码区174-194位点的siRNA序列及其应用 | |
| CN107058330B (zh) | 一种mzf1蛋白可结合dna片段及在mzf1活性检测中的应用 | |
| CN107034215B (zh) | 一种cux1蛋白可结合dna片段及在cux1活性检测中的应用 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17806675 Country of ref document: EP Kind code of ref document: A1 |
|
| ENP | Entry into the national phase |
Ref document number: 2018520924 Country of ref document: JP Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 3026340 Country of ref document: CA |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| REG | Reference to national code |
Ref country code: BR Ref legal event code: B01A Ref document number: 112018075010 Country of ref document: BR |
|
| ENP | Entry into the national phase |
Ref document number: 2017275184 Country of ref document: AU Date of ref document: 20170530 Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 20187037821 Country of ref document: KR Kind code of ref document: A |
|
| ENP | Entry into the national phase |
Ref document number: 2017806675 Country of ref document: EP Effective date: 20190103 |
|
| ENP | Entry into the national phase |
Ref document number: 112018075010 Country of ref document: BR Kind code of ref document: A2 Effective date: 20181203 |